(第2回)ニューラルネットワーク
自然言語処理でもニューラルネットワークを利用して進めます。MNISTでは基本的な部分から始めましたが、今回は レイヤを利用して、まとめてみます。
<2層 ニューラルネットワーク>
レイヤを利用して2層のニューラルネットワークをPythonで作成します。
第1回と同じ構成ですが、クラスを利用して呼び出す事で、複雑になっても理解しやすくなっています。
同じような出力が得られます。順伝播のみがプログラムされていますが、今後、逆伝播が不可欠になってくるので、 このプログラムの方が効率よく処理が可能です。
$\large{X→\begin{bmatrix} \\Affine \\ \end{bmatrix}→\begin{bmatrix} \\Sigmoid \\ \end{bmatrix}→\begin{bmatrix} \\Affine \\ \end{bmatrix}→S}$
上記がレイヤの構成になります。2層のニューラルネットワークですが、レイヤが3個あるので、入力~出力の間に3つのレイヤがあることを表しています。
<2層 ニューラルネットワーク+損失関数>
2層のニューラルネットワークに損失関数を接続します。損失は最適なパラメータを推測するために現状のパラメーターがどうなのか?評価するために
重要な関数になります。
プログラムを書いてみます。
結果
損失関数が追加されていますが、出力が3次元なので、正解ラベルは、行列(10x3)から10個の0~2のラベルに変換されます。10個のランダムデータですが、 損失関数は入力の最大と同じ要素が正解の場合は、値が小さく、不正解の場合は大きくなっていることがわかります。
$X→\begin{bmatrix} \\Affine \\ \end{bmatrix}→\begin{bmatrix} \\Sigmoid \\
\end{bmatrix}→\begin{bmatrix} \\Affine \\ \end{bmatrix}→\begin{bmatrix} \\Softmax \\
\end{bmatrix}*)→\begin{bmatrix}Cross \\Entropy \\Error \end{bmatrix}→L$
*)正解ラベルの追加位置: $t→$
上記がレイヤの構成になります。
<計算グラフ>
ニューラルネットワークの学習をする場合、順伝播と逆伝播を計算して、パラメーター(重み、バイアス)を変更します。
順伝播で微分をして勾配を求めながら、パラメーターを変更することもできますが、計算負荷が大きすぎるため、現実的ではありません。
順伝播と逆伝播を理解するために、計算グラフを用いると理解がしやすいため、調べていきます。
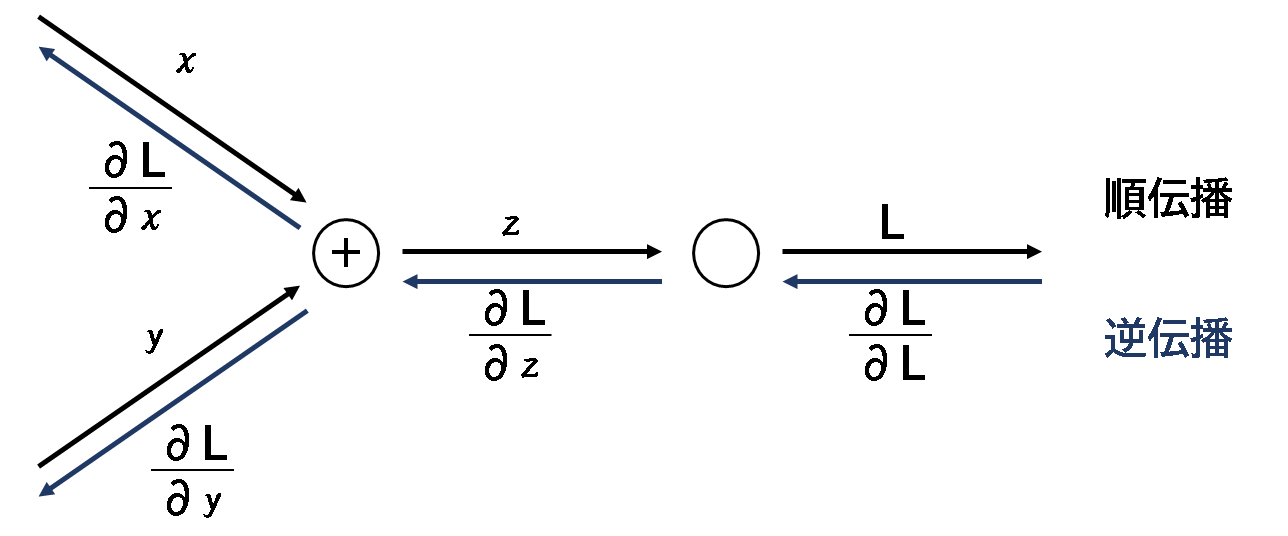
<ノード①>
加算、乗算、分岐ノードについてです。加算は、出力をそのまま戻す形、乗算は、出力に順伝播の入力を入れ替えて、 分岐は、分岐した物を足し算するような方法でそれぞれ逆伝播します。分岐ノードはコピーノードとも言うそうです。
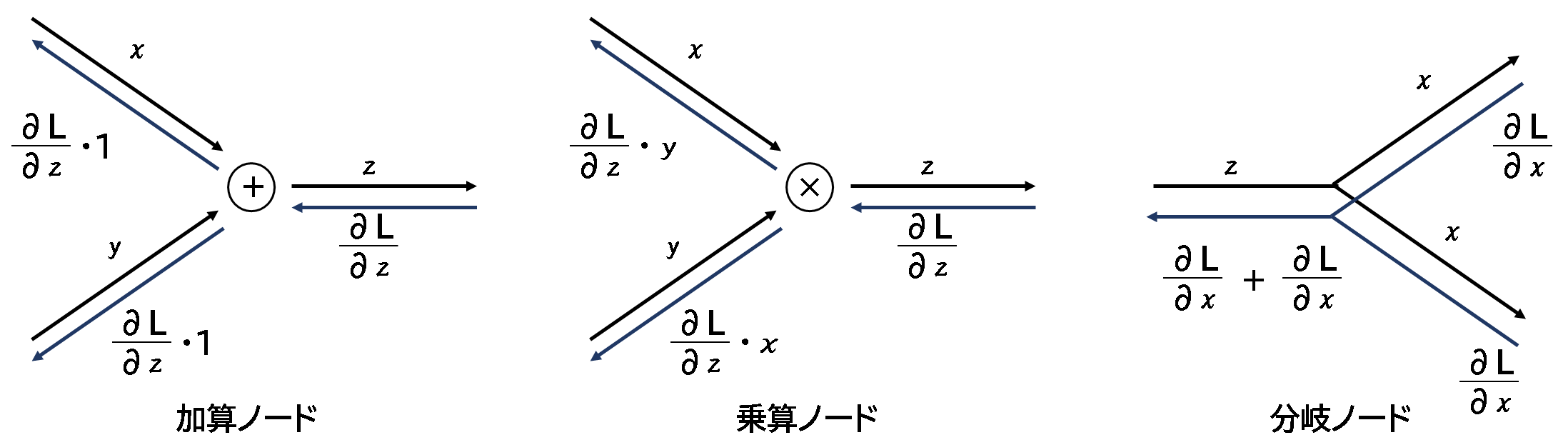
<ノード②>
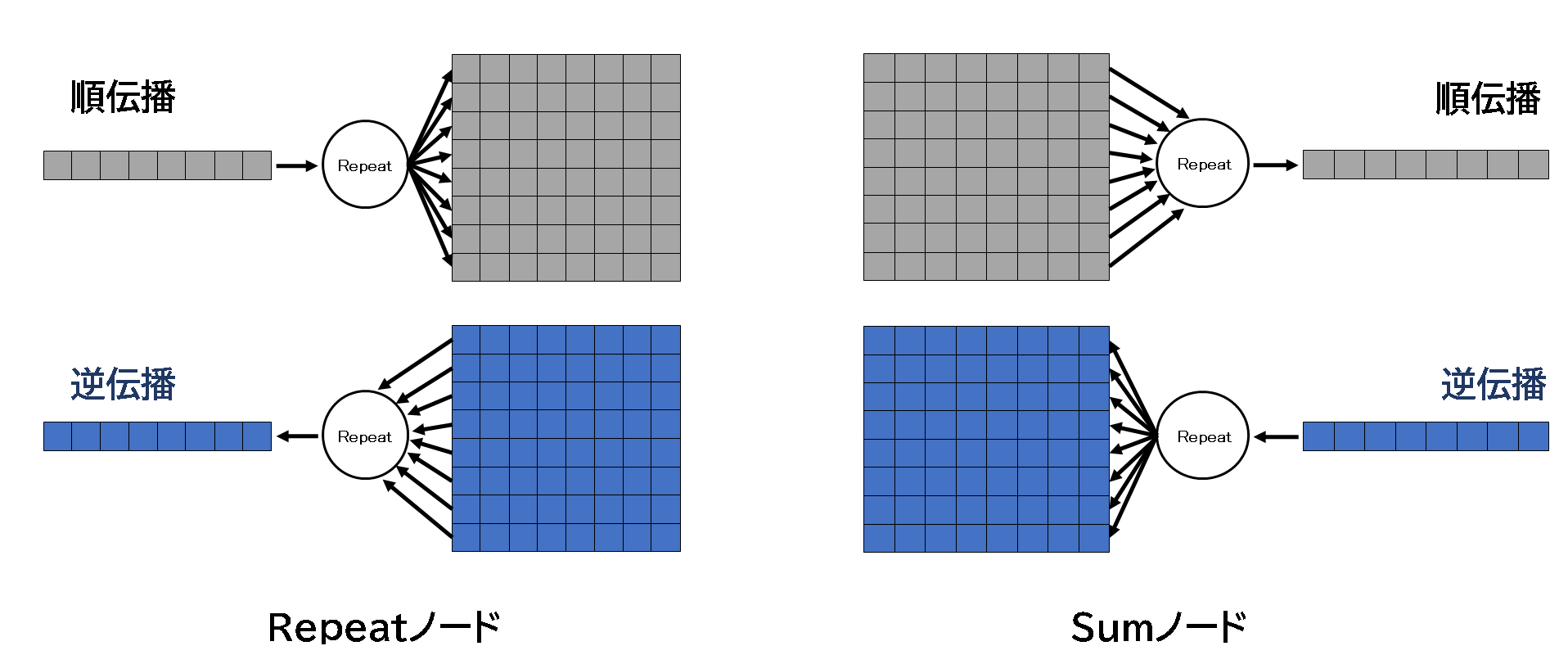
分岐は1個だけでしたが、複数に対応したRepeatノード、Sumノードを見てみます。順伝播、逆伝播とも同じ列数ですが、 Repeatは1→N行へ分岐(コピー)、SumはN→1行への加算(集約)がされていることが特徴的です。
Pythonで書くと以下のとおりになります。
出力を確認すると、図のように順伝播、逆伝播が表示されています。keepdims=Trueは2次配列保持。axis=0は行方向の 分岐(repeat)や総和(sum)を求める形になります。
<ノード③>
行列の積をMatMalノードという形で計算します。形状は以下のとおりで、順伝播、逆伝播次の式で 計算されます。
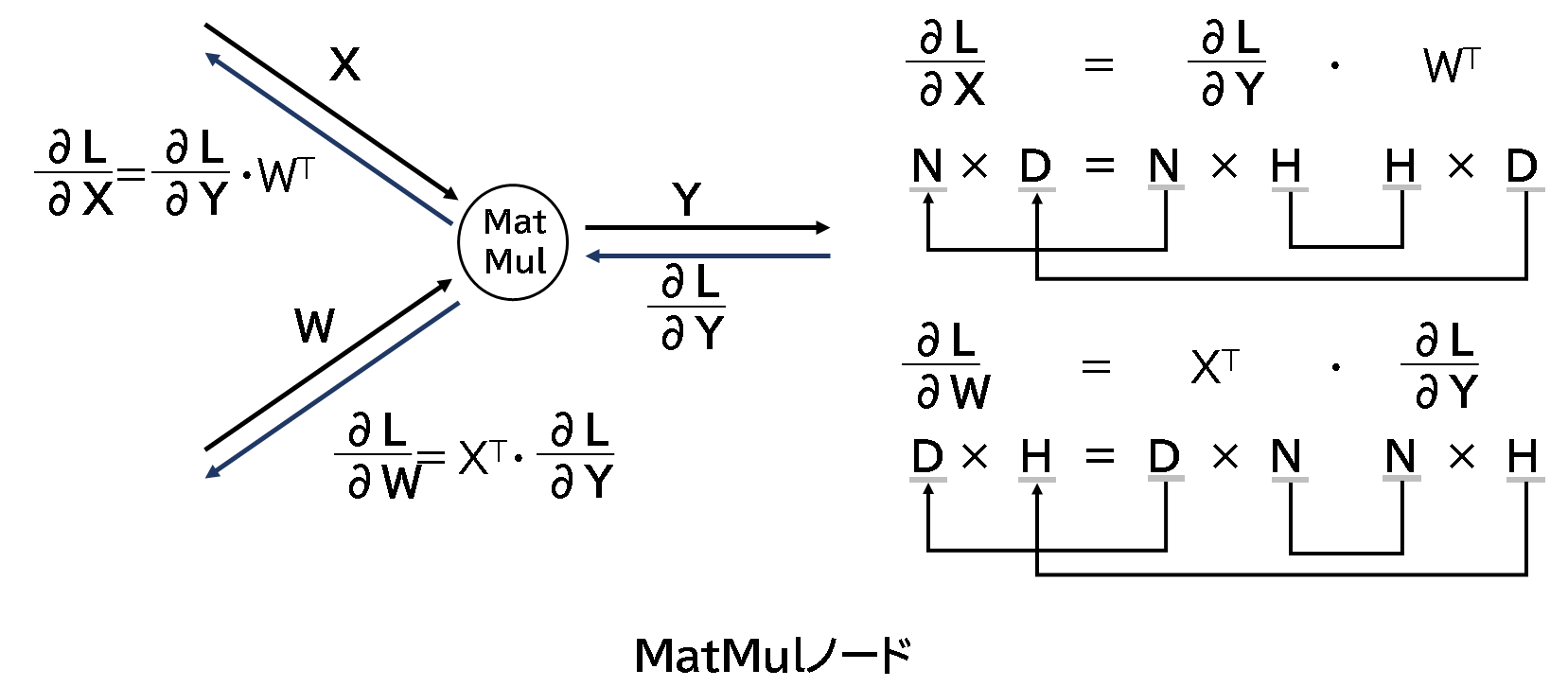
Pythonで書くと以下のとおりになります。
入力Xと重みWの行列の積を順伝播で出力して、そのまま逆伝播でdx,dwを表示させています。 同じ形状の行列が逆伝播の戻り値が得られています。
<Affineレイヤ>
MatMal、Repeatノードを使うと以下のようにAffineレイヤを計算グラフで表すことができます。
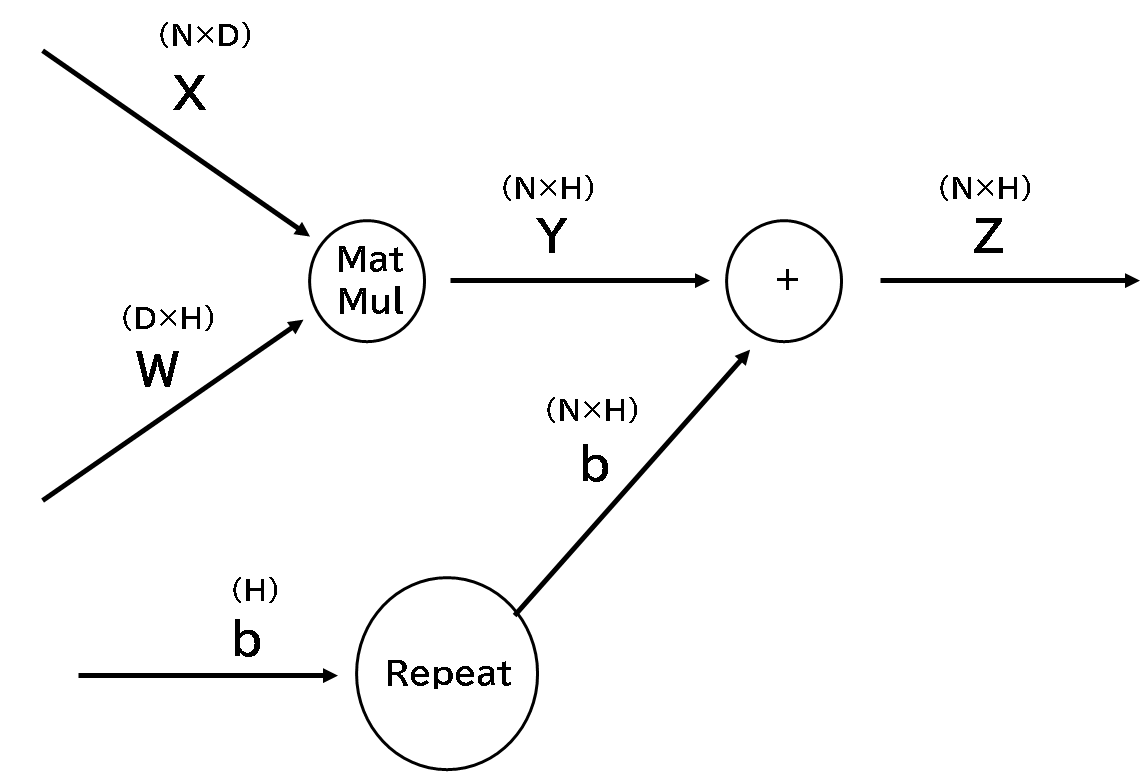
Pythonで書くと以下のとおりになります。
入力Xと重みWの行列の積を順伝播で出力して、そのまま逆伝播でdx,dwを表示させています。 同じ形状の行列が逆伝播の戻り値が得られています。
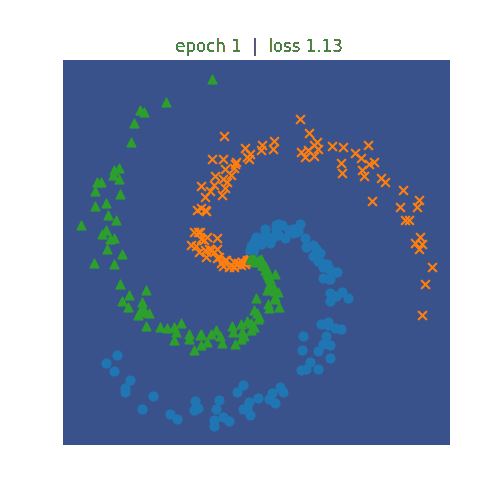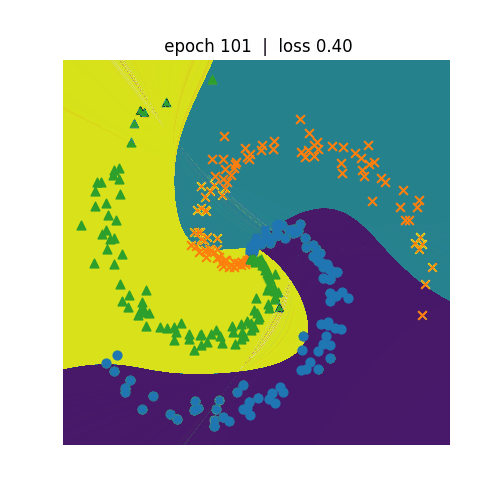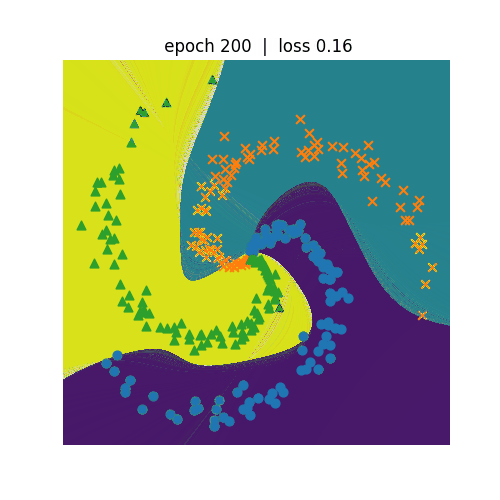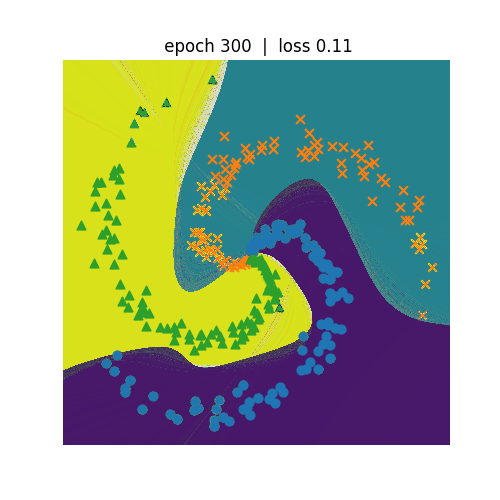
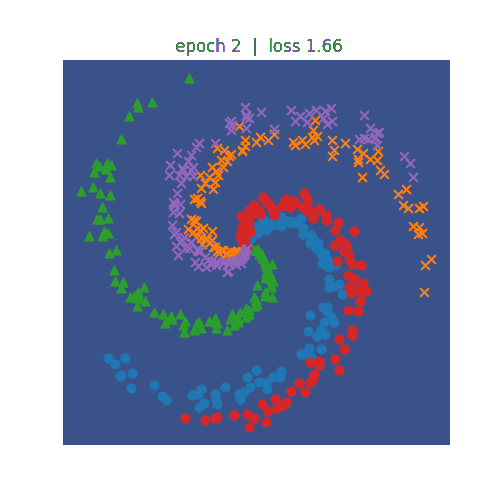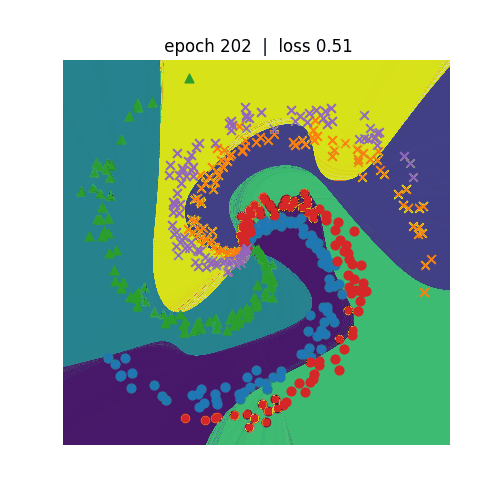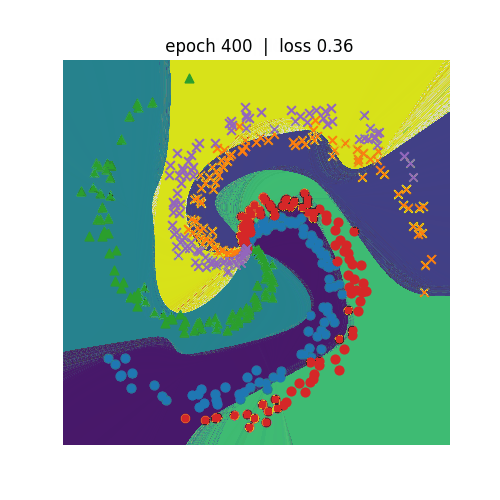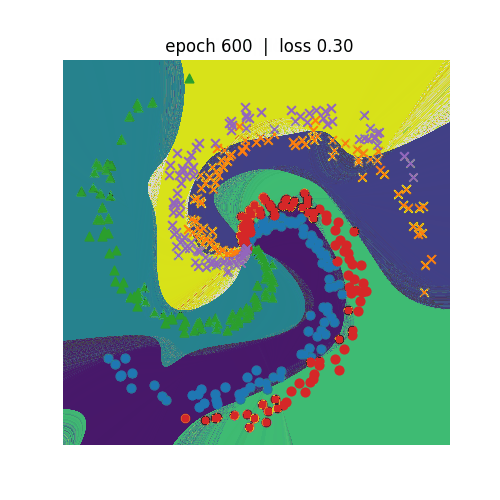
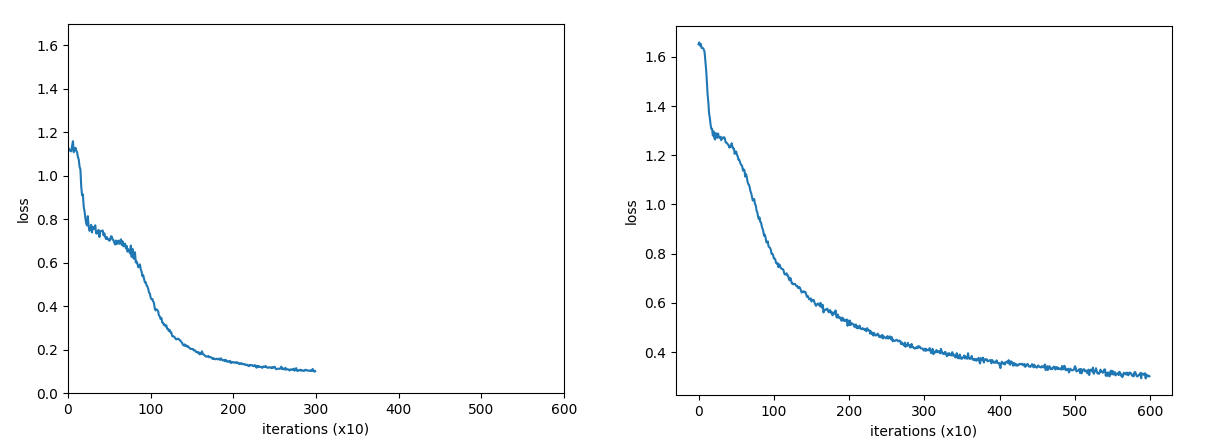
<Spiralデータセット分類>
(参考サイト)https://github.com/oreilly-japan/deep-learning-from-scratch-2
ニューラルネットワークを利用して非線形の分類を行います。左側がN=3、右側がN=5の分類を行うプログラムになります。 N=5の方が学習のepochが600まで進めてもloss(誤差)は0.3程度までしか低減しません。N=3の方は、epochが300でも loss(誤差)は0.1まで低減しています。どちらも学習が進むにつれて、種類が違う点を分割しようという意図が伝わってくるような 動きになっています。
-------------