(第5回)Word2Vecその②
推論ベースで短いコーパスでは処理ができましたが、PTBデータセットの単語数ではone-hot表現が現実的なサイズではないので、
この部分を対応する必要があります。もう1点重みの出力側でもおなじように大きな行列で処理することになるので、同様に対応が必要です。
①入力のone-hot表現(Win)
②Woutの積とSoftmax
この2つの対応をしないと実用的なものになりませんので、調べていきます。
<Embedding>
Embedding=埋め込みという意味でEmbeddingレイヤを実装することで、①のone-hot表現の対応をします。具体的には、
1度にすべてのコーパスを行列にするのではなく、コーパスからランダムで選択したテキストをバッチ処理する方法になります。
バッチサイズ毎に順伝播、逆伝播を行い学習をすすめる事になります。①だけの順伝播、逆伝播を以下の図で表します。
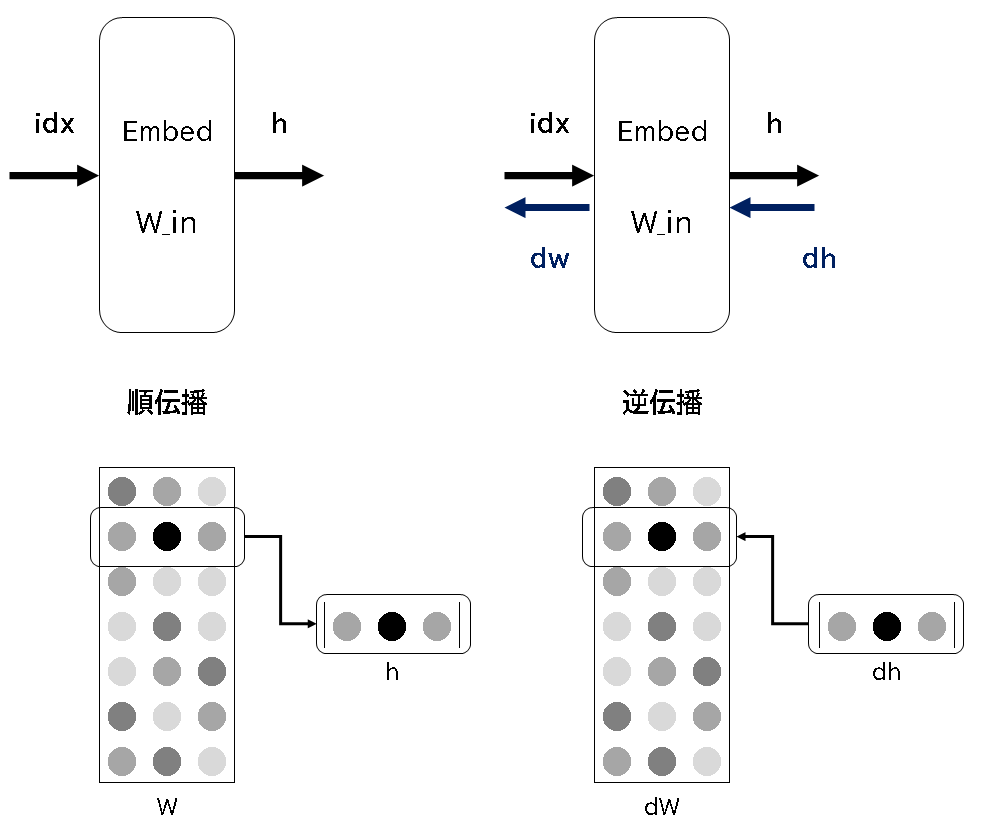
順伝播時は、単純にWから指定した行を抜き出すだけです。逆伝播の場合も同じ用に、 前の層(例えば出力側の層)から伝わってきた勾配を次の層(入力側の層)へそのまま伝えるだけになります。
Pythonでそれぞれオプログラムを書いてみます。
順伝播、逆伝播ともにidx=2として考えてみると、順伝播の場合は、[6,7,8]が出力側へ伝達され、逆伝播は、[0,1,2]が
入力側に伝達されています。また1個だけ更新することは無く、複数個更新する場合もコメントアウトしてあります。
特に同じidx番号に逆伝播される場合は、加算されるという点に注意が必要です。
MatMalからEmbeddingにすると計算が早くなります。
-------------