(第3回)自然言語と分散表現
自然言語処理では単語の意味(正確にはベクトル)を学習して、膨大な文書を集約(その文章の要約)したり、翻訳をしたり します。Googleで毎日のように検索して、抽出されたアドレスを見ていますが、これも自然言語処理が利用されています。まずは 自然言語処理における単語の原始的な考え方について調べてみます。
<シソーラス>
人間が言語の意味をコンピューターに登録する方法です。日々更新される単語(スマホ=スマートフォン)を随時変更していくのは、
かなり大変ですが、単純なプログラムは作成ができそうです。
まずは、シソーラスの代表的なライブラリのWordNetを使ってみます。そこでPythonのライブラリである、
ntlkをインストールしておきます。
pip install ntlk
以下がPythonのプログラムです。初回のみダウンロードが必要です。(3GB越えの容量になります・・・^^;)
車の同類にオートモービルや乗用車、犬の同類にイヌや洋犬などが出力されます。
<カウントベース>
コーパスというテキストデータを使って、意味を抽出します。シソーラスのように人力に頼らないため、
自動化はできますが、利用するテキストデータと目的が一致していないと利用価値がなくなってしまいます。
そしてコーパスを作成するためには単語の切り取りが必要になります。
以下がPythonのプログラムです。短い英語の文章ですが、単語をID化して、その文書をIDとして表現されています。
英語なのでスペースがあれば、単語として抽出が可能ですが、日本語は・・・・^^;
<分散表現>
シソーラスのように人力に頼らずに単語の意味を理解するために必要な考え方になります。MNISTでは画像の明るさを
学習の入力として利用し、数値が出力(これを正解させる事が目的)していました。単語でも数値として扱うため、分散表現を利用します。
具体的には、単語のベクトルとして表現し、その数値を使って学習させるという方法になります。簡単にできるのは、文章からと周辺の単語の
関係性を利用する方法になります。まずは簡単な行列で表現してみます。
以下がPythonのプログラムです。各単語の近い単語を抽出して行列で表現します。
行列で表現ができるようになりました。
下の図が、出力された数値を表にしたもので、各単語に近い(となり)単語が1として表現されています。
これを共起行列といいます。

<ベクトルの類似度>
分散表現で単語のベクトルが表現できるようになったので、ベクトルの類似度をコサイン類似度によって表現します。
類似度を算出することができるとどの単語が似ているのか?を数値によって表現ができるようになります。
〇コサイン類似度
2つのx.yのベクトルがある場合、下の式のとおりになります。
$\large{x=(x_1^2+x_2^2+x_3^2+・・・x_n^2)}$
$\large{y=(y_1^2+y_2^2+y_3^2+・・・y_n^2)}$
$\large{コサイン類似度=\frac{x・y}{||x||・||y||}}$
$\large{=\frac{x_1y_1+x_2y_2+x_3y_3+・・・x_ny_n}{\sqrt{x_1^2+x_2^2+x_3^2+・・・x_n^2 }・\sqrt{y_1^2+y_2^2+y_3^2+・・・y_n^2 }}}$
実行すると以下の数値が出力されます。
0.7071067691154799
コサイン類似は-1~1なので、近い数値になっています。実際は、sayやand以外はyouに対して
同じ数値が出力されます。これは、コーパスが小さすぎるためです。
〇類似度ランキング
類似度が出力できたら、ランキングを計算させます。
ランキングを計算することで、さらに単語間の距離が分かり易くなります。自然言語処理のなかでも
単語間の関連性を確認するときに順序を見ることが良くあります。
次がプログラムになります。
実行するとYouに対するランキングが出力されます。
コーパスが小さすぎるため参考になりませんが、ちゃんと出力されています。
<PPMI(正の相互情報量)>
PMI(相互情報量)は2つの単語が共起した回数を数えて、算出します。
$\large{PMI(x,y)=\log_{2}{\frac{P(x,y)}{P(x)・P(y)}}}$
$p(x)$はコーパス内にxが何個あるかということで、
$P('car')=\frac{20}{1000}$は1000単語あるコーパス内にcarが20個含まれているという意味です。
$P(x,y)$はコーパス内にxとyの共起が何個あるかということで、
$p('car','dog')=\frac{10}{1000}$は1000単語あるコーパス内にcarとdogの共起が10個含まれているという意味です。
$C$・・・共起行列
$C(x)$・・・xの出現
$C(y)$・・・yの出現
$C(x,y)$・・・xとyの共起する回数
$N$・・・コーパス単語数(共起行列の合計)
$\large{PMI(x,y)=\log_{2}{\frac{\frac{C(x,y)}{N}}{\frac{C(x)}{N}・\frac{C(y)}{N}}}}$
$\large{PMI(x,y)=\log_{2}{\frac{C(x,y)・N}{C(x)・C(y)}}}$
コーパス内にdogが30個含まれていると
$\large{PMI(car,dog)=\log_{2}{\frac{10・1000}{20・30}}}=4.059$
$\log_{2}$は1より小さいとマイナスになりますが、PPMIは
PMIのプラス側のみの情報になります。マイナスの時は0にしているので、正のみの情報です。
次がプログラムになります。
実行すると先ほどの共起行列がPPMIの数値になって出力されています。
[hello][.]の場合は、
$\large{PMI(’hello’,’.’)=\log_{2}{\frac{1・14 }{2・1 }}}=2.8073$
[say][goodbye]の場合は、
$\large{PMI(’say’,’goodbye’)=\log_{2}{\frac{1・14 }{4・2 }}}=0.8073$
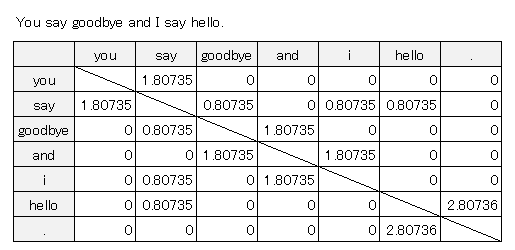
表にすると共起行列で1の部分が数値があります。先ほどはすべて1でしたが、相互情報量を表現することで、 数値に変化が生まれています。
<次元削減>
特異値分解(SVD)をつかって次元削減を行います。
PPMIの表をみるとわかりますが、0が多いので、情報量としていらない物があります。そこで、次元削減を行い
必要な情報を残しつつ、データを圧縮していきます。
実行すると先ほどの共起行列にSVDが適用されます。この行列の先頭の2次元を抜き出すと2次元に削減される
ことになります。
2次元にした物をグラフにします。
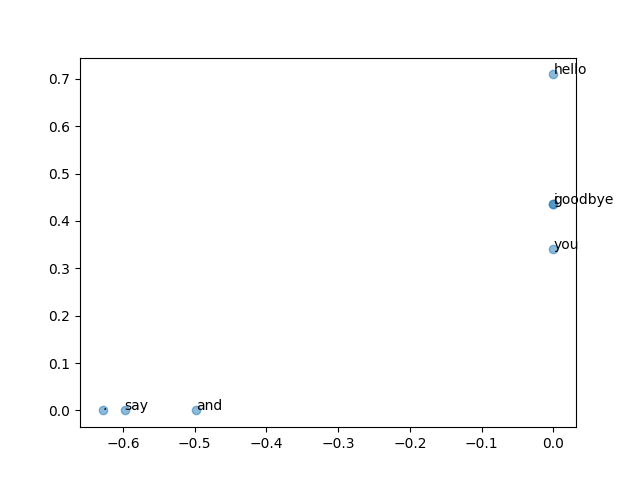
コーパスが小さすぎて意味はないですが、「i,you,hello」 「say,and,.」でグループができているように見えます。
<PTBデータセット>
ペン・ツリー・バンク(PTB)というデータデータセットを利用して、いままでのプログラムを動作させてみます。
少し時間はかかりますが、入力した単語に近い類似した単語を出力させることができます。
色々な単語を見てみたいのですが、上のプログラムだと毎回十分程度時間がかかるので、時間のかかる出力の、PPMIと
SVDを経由した出力のU、V、Sをpikleファイルとして保存して、1度実行したら、そのファイルから読み出すようにします。
読み出すプログラムは以下のようになります。
上のプログラムの
querys=['you','year','car','toyota','dog','disney']
の単語を変更すると記載した単語の近い単語が出力されます。以下が出力したデータです。
今回は自然言語処理についてしらべてみました。実用性は全くないですが、どのようにして単語を数値化するか?など 興味深い内容だったです。PTBのデータセットも英語ですが、類似している単語がちゃんと表示されています。データファイルに 「ptb.test.txt」がありますが、内容をみるとNEWSの記事のような物が保存されており、TOYOTAの近いものにNISSANや HONDAなど「なるほど」と思うような単語が出力されていて、感心しました。
-------------