(第4回)Word2Vec
カウントベースの手法で単語の分散表現から類似語を抽出してきましたが、推論ベースでの単語の分散表現を
行い、同じように類似語を抽出していきます。その手法がWord2Vecになります。
カウントベースでは、膨大な単語の共起行列(1万単語=1万×1万の行列)を作る必要がありましたが、推論ベースでは
単語毎に100次元程度のモデルでも類似語が抽出できるようになります。Word2Vecについて調べていきます。
<推論ベース手法>
まずは推論ベースでどのように単語を推論するか?になります。CBOWは周囲の単語=コンテキストから、目的の単語を 推測するという方法になります。Skip-gramはターゲットの単語から周囲の単語(コンテキスト)を推論します。
[you][???][goodbye][and][I][say][hello][.]・・・CBOW
[???][say][???????][and][I][say][hello][.]・・・Skip-gram
???の単語を推論するために、文=コーパスから周囲の単語=コンテキストやターゲットの言語を入力して、推論したい単語を
出力する方法になります。入力と出力の間に重み=Wがあります。
まずは、入力と中間層を図にすると以下の通りになります。入力には単語IDをone-hot表現にして、重みを経由して、
中間層に出力させています。
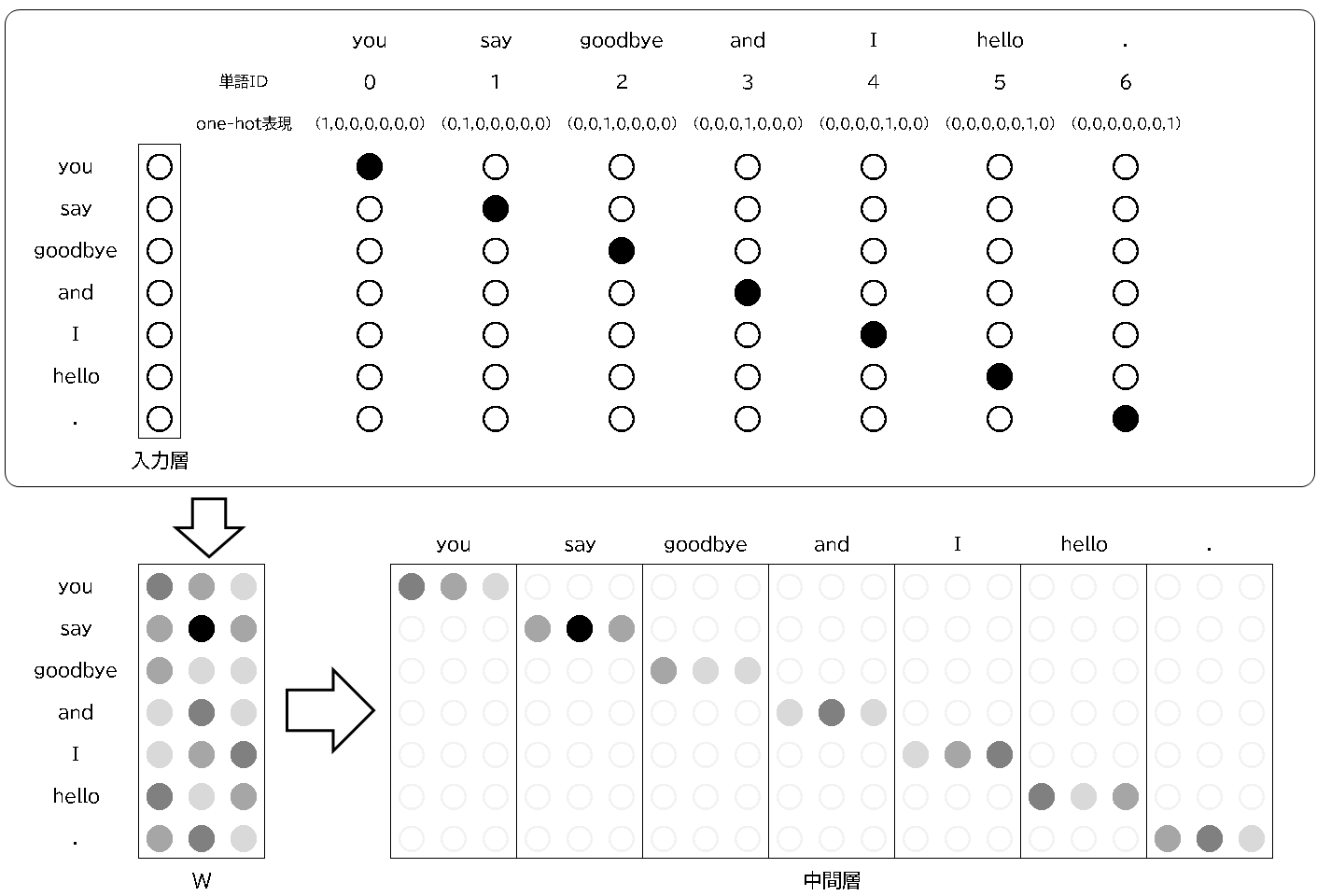
〇ニューラルネットワークでの出力
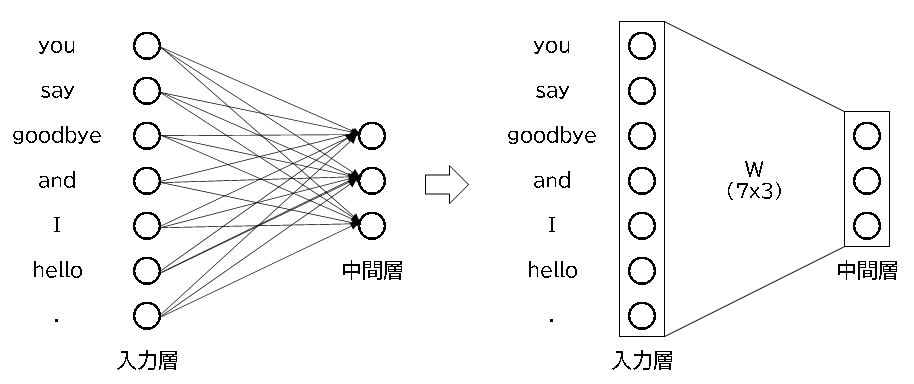
ニューラルネットワーク的に表現すると以下の通りです。入力層から中間層の間に重みがあり、これなら学習して 入力から出力を得られそうです。
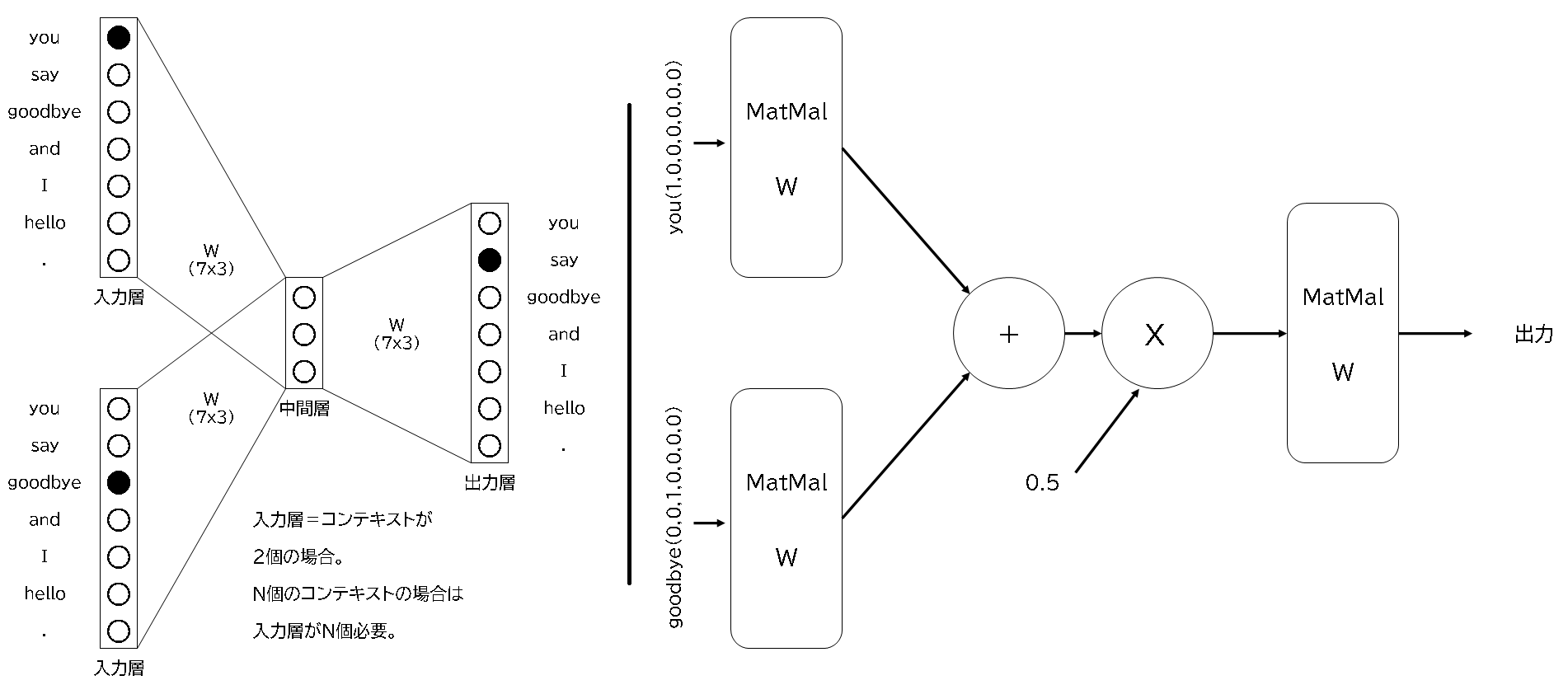
CBOWの場合で具体的に表現すると以下の図のとおりになります。コンテキストが2個ありますので、入力層が2個あり、中間層を経由して、出力層から出力が得られます。 例えば、youとgoodbyeの間がsayの出力が得られるように中間層を経由させて、重みを調整することになります。途中で0.5が掛け算されていますが、 2つの入力層のための1/2です。
いよいよPythonでプログラムを書いてみます。
重みはランダムなので、出力もランダムですが、ニューラルネットワークの構造はできました。 入力から中間層を経由して出力されています。これを学習させて、目的の出力ができれば、良さそうです。
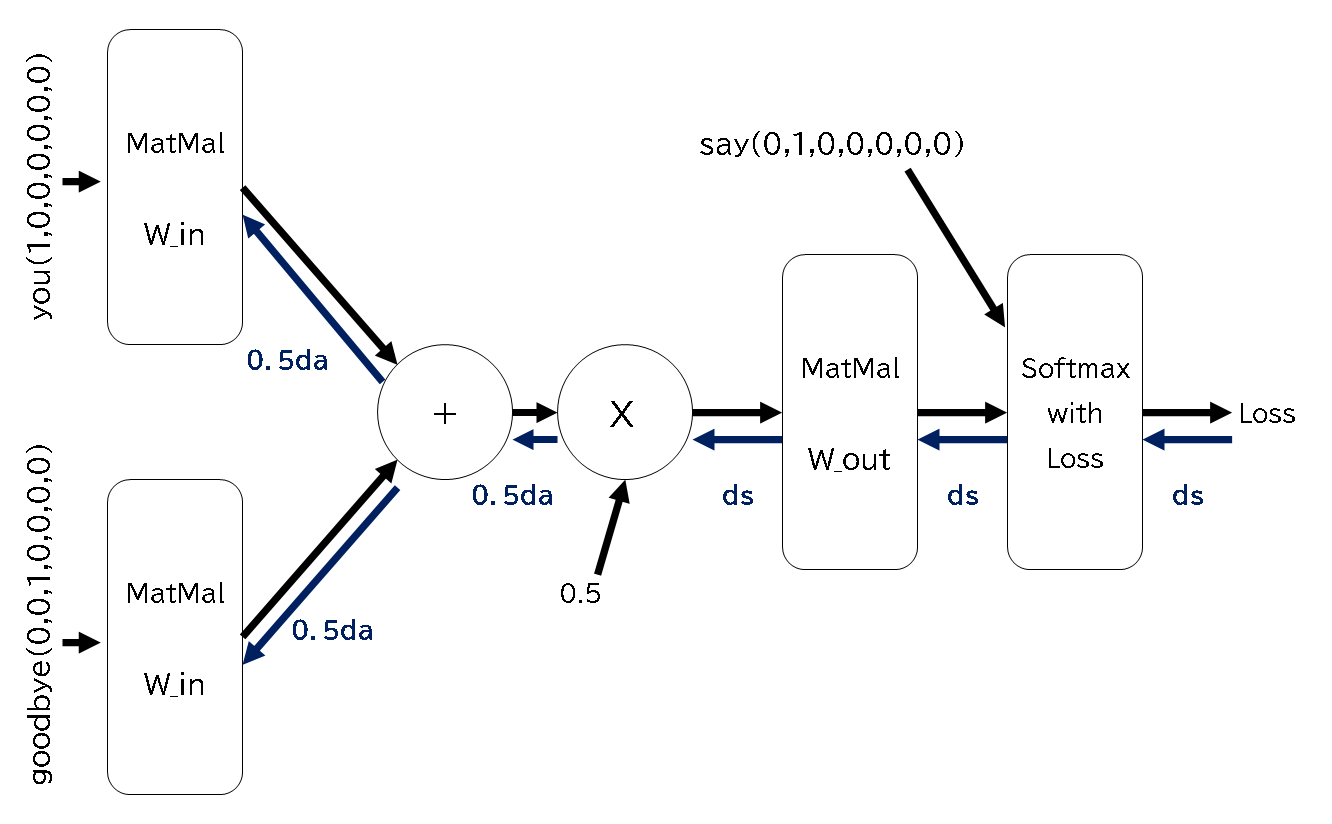
〇CBOWでの学習
出力ができるようになったので、実際に学習させてみたいと思います。MNISTと同じように逆伝播を行い、 誤差の計算をして重みを変更していきます。以下が学習させるときのモデルになり、逆伝播も示しています。
以下がプログラムになります。短いコーパスですが、少々長いプログラムになっています。
損失をグラフにすると下のとおり出力されます。
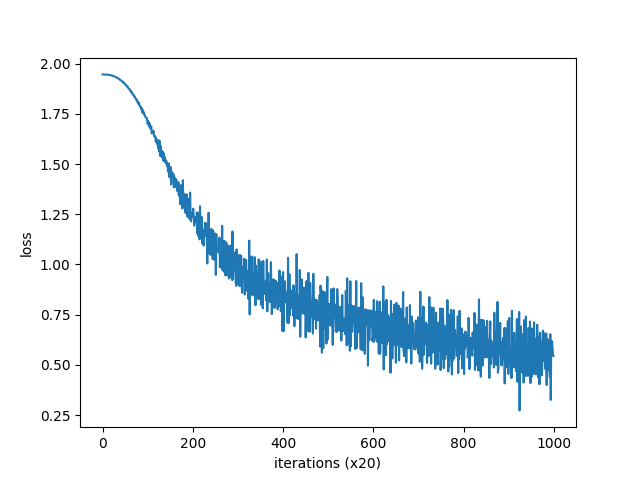
〇Skip-gramでの学習
CBOWと推測の方法が違うSkip-gramは構造を描くと以下のような感じだと思います。 ターゲットの単語から周囲の単語のコンテキストを推測していきます。出力側の正解が複数になっているので、 それぞれの正解をSoftmax with Lossにいれて誤差を計算します。
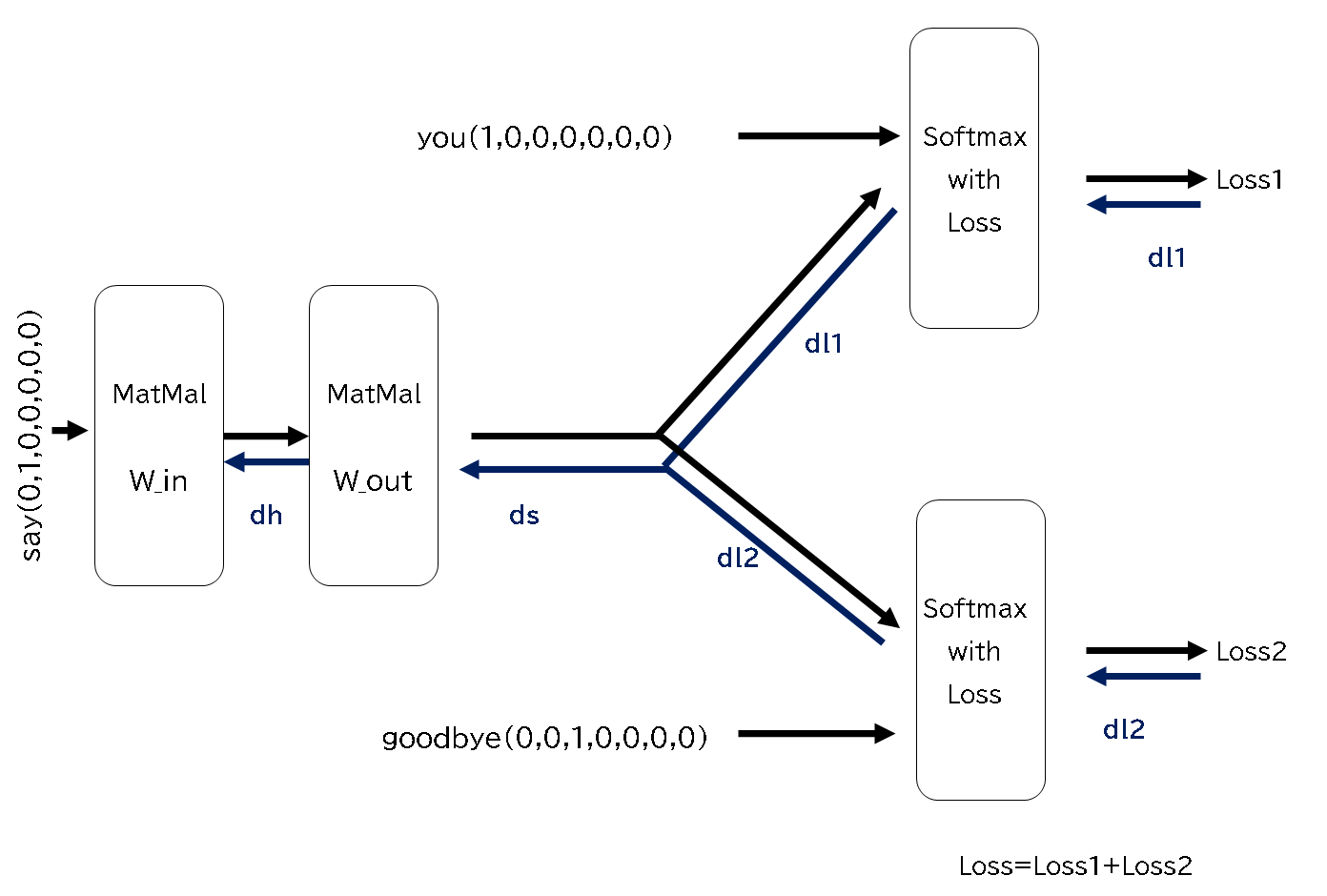
Skip-gramでもプログラムを作成して学習させてみます。最後の誤差は2つありますが、加算してグラフにします。
損失をグラフにすると下のとおり出力されます。
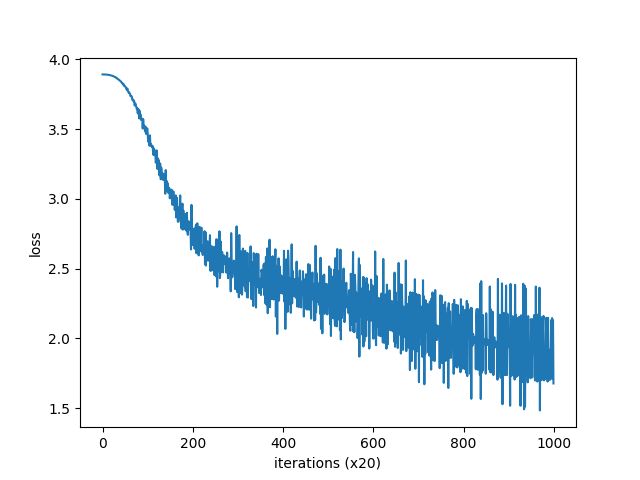
最後にPTBデータセットをこのプログラムに適用してみます。
numpy.core._exceptions._ArrayMemoryError: Unable to allocate 34.6 GiB for an array with shape (929579, 10000) and data type int32
エラーが出てしまいます・・・。「target = convert_one_hot(target, vocab_size)」の部分なのですが、shape (929587, 10000)
という行列が大きすぎるため、one-hot表現ができないためです。10000単語を処理するためには・・・。
-------------