(第10回)重みの初期値
学習をすすめると重みが変更されていきます。学習の目標は汎化性能を高くすることですが、重みの初期値によって学習がすすまなくなることも あります。今回は、この重みの初期値について調べてみます。
<Sigmoid、ReLU、Tanhの初期値>
Sigmoid、ReLU、Tanhの初期値を0.01~1にへ変更したときの差を比較します。重み結果(アクティベーション)のヒストグラムのグラフを確認してみます。
次のプログラムを実行すると、それぞれの関数のグラフを作成できるようになっています。
実行すると以下のグラフが作成されます。(1種類づつ出力)
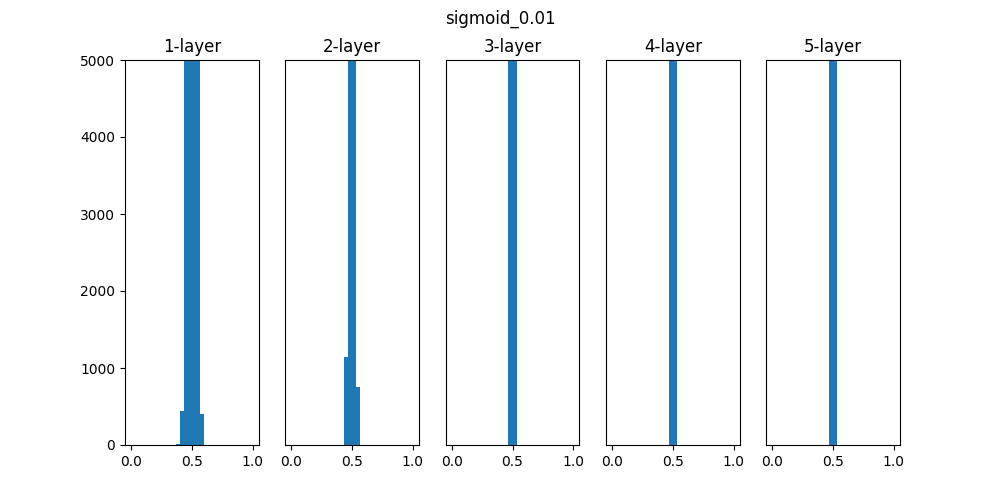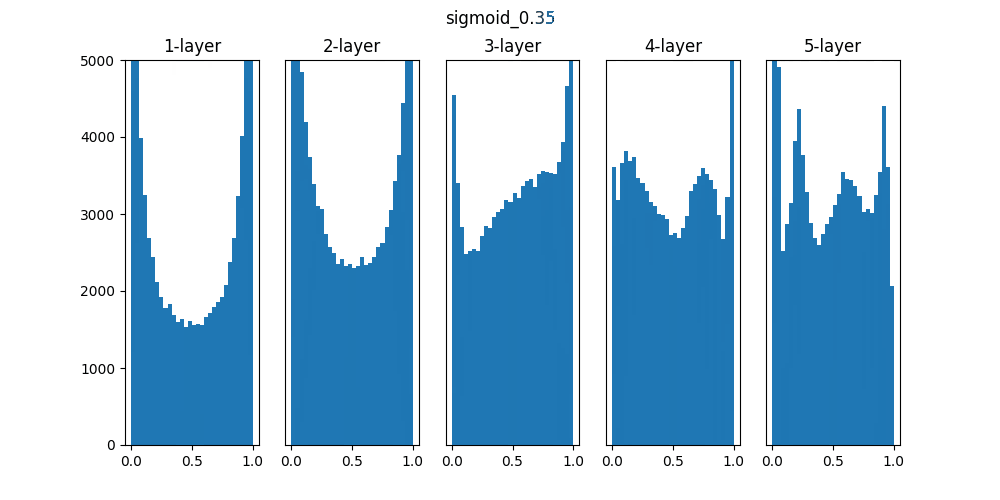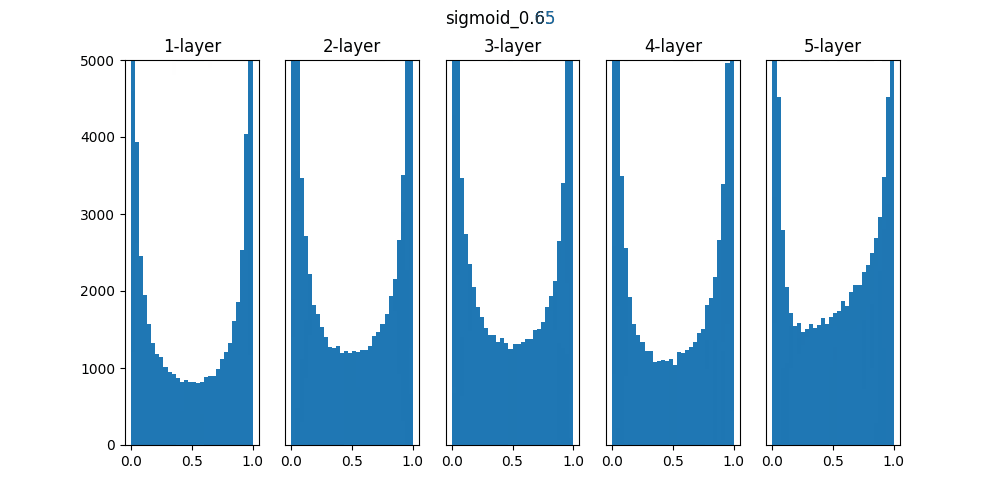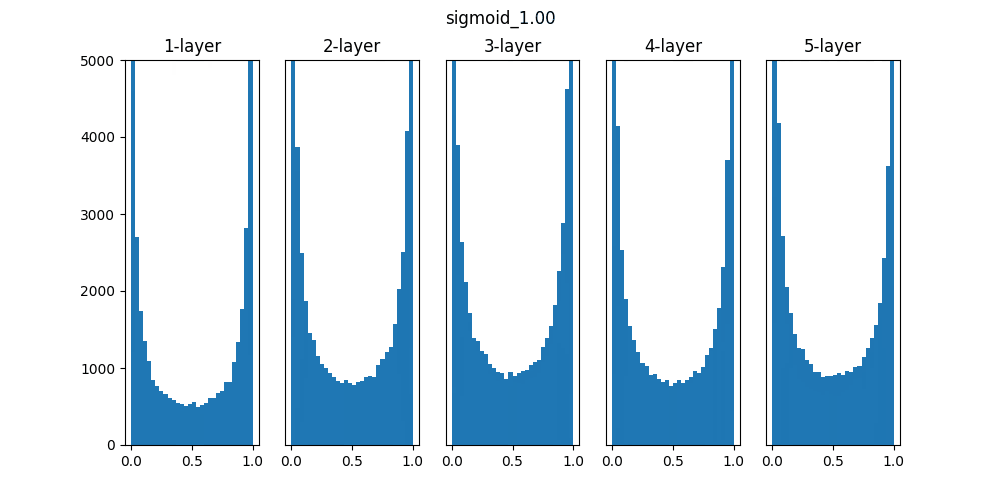
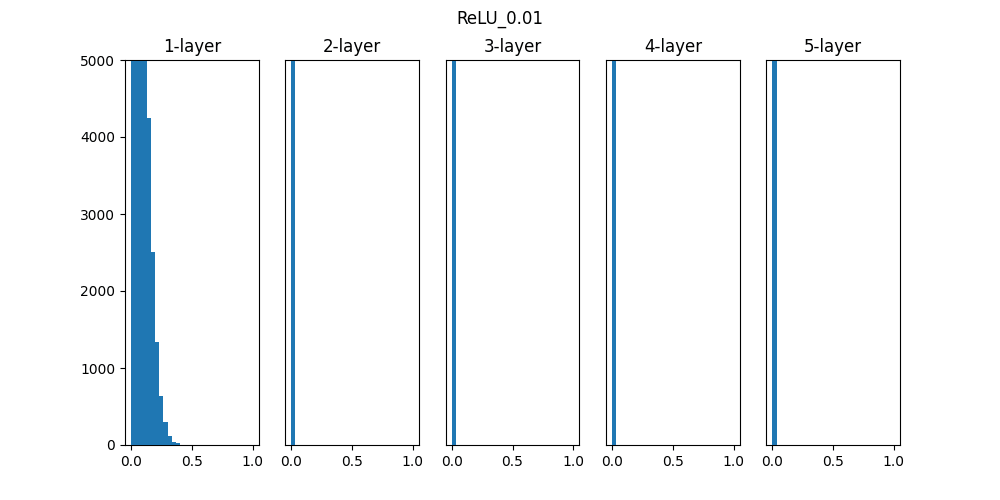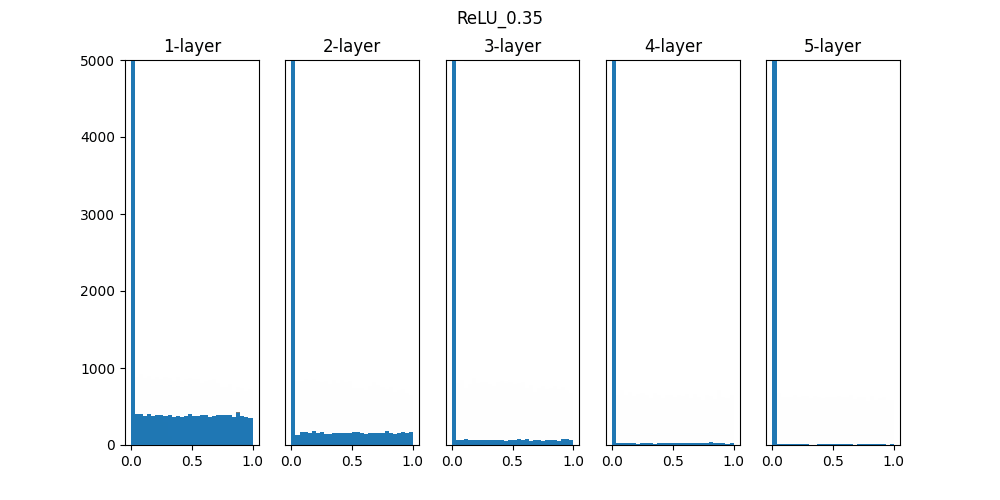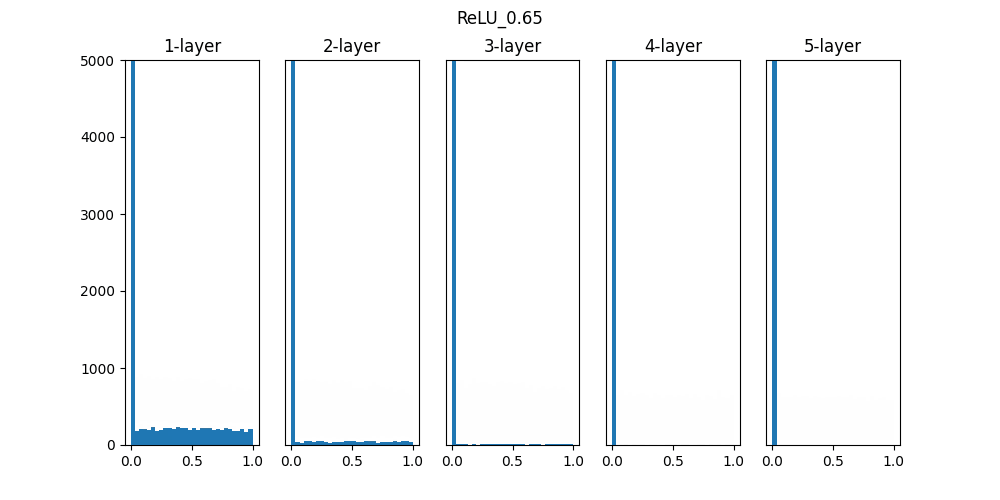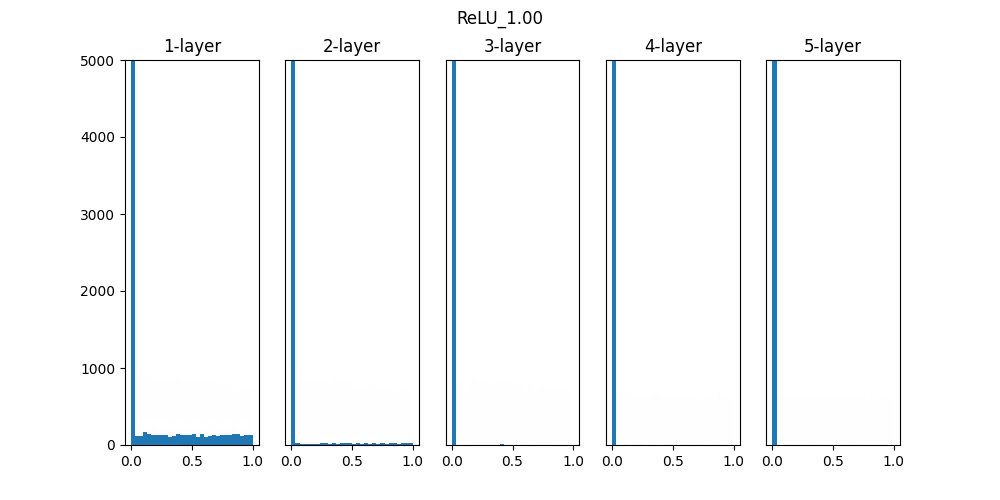
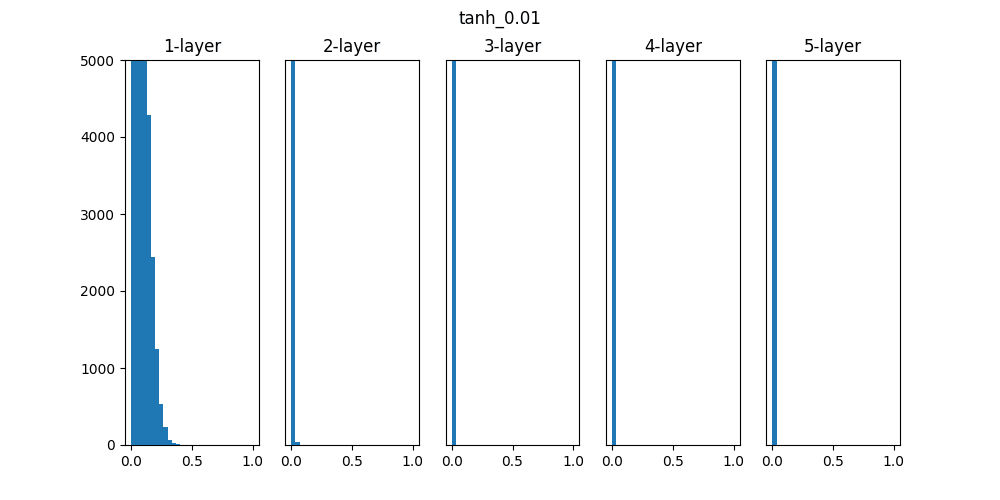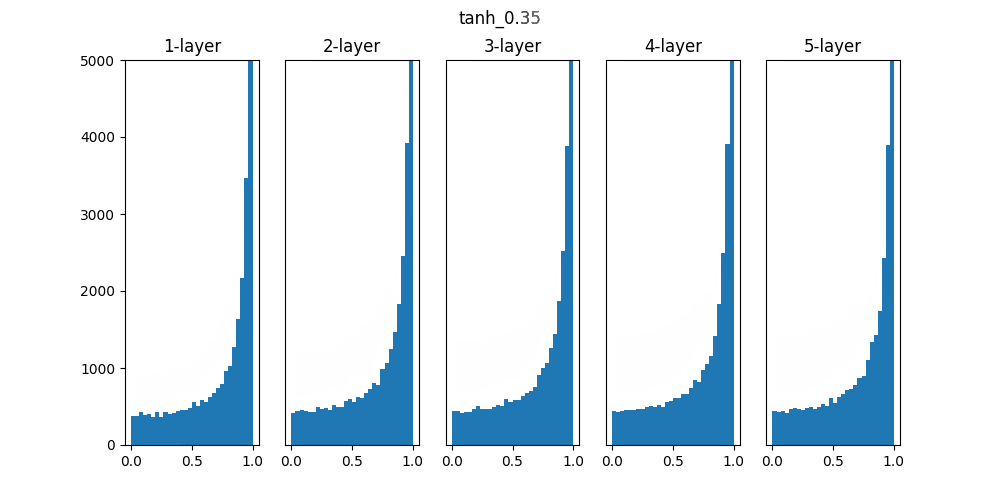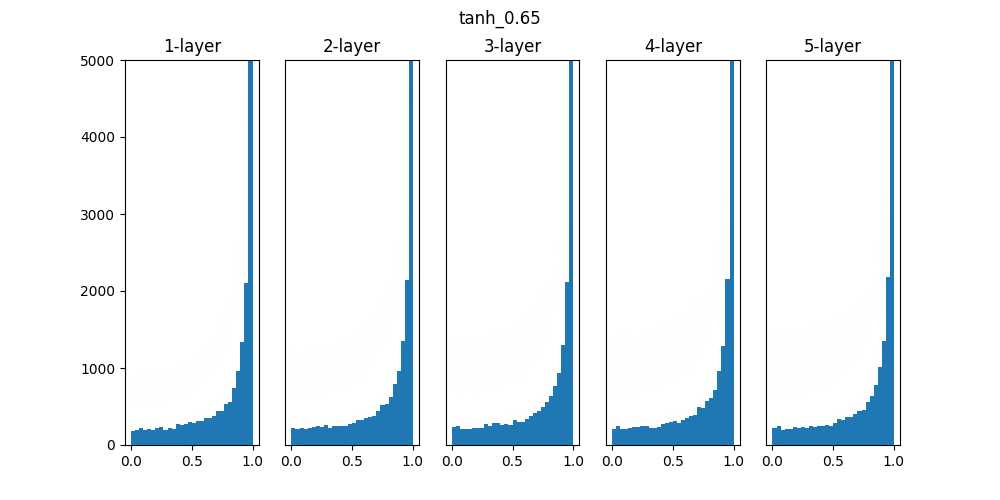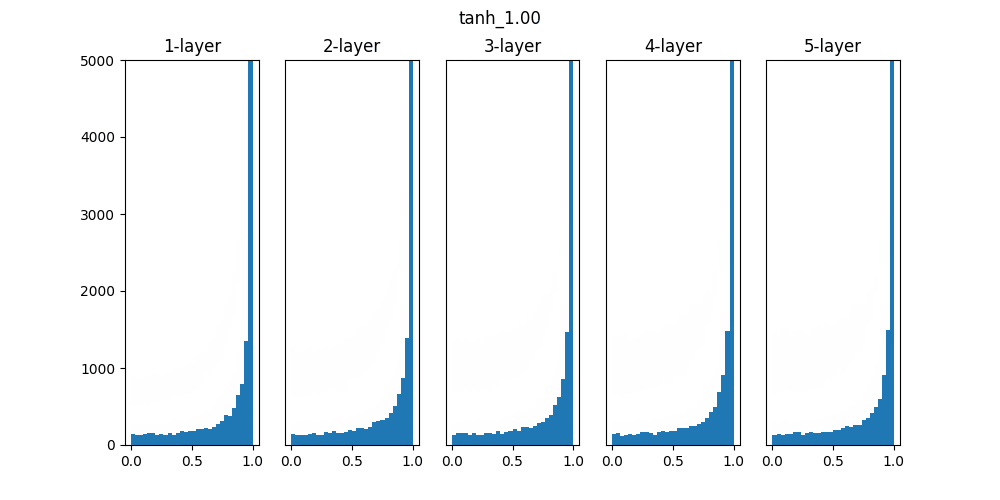
Sigmoidは0.01の時は中央に集中していますが、初期値を1になると0と1に偏った分布になっており、勾配消失が発生してしまっています。
ReLUは0に分布が集中し、Tanhは-1~1の曲線なので、0に集中した状態から1に集中するような分布になっています。
重みの初期値によっても活性化関数の種類でも分布が変わるので、学習の結果に差異が生まれることが良くわかります。
〇Xavier初期値
SigmoidやTanhの場合は、左右対称で中央付近が線形関数となっているので、この関数をつかって初期値にします。
$\sqrt{\frac{1}{n}}$ *)nは前層のノード数
〇He初期値
ReLU関数専用の初期値です。
$\sqrt{\frac{2}{n}}$ *)nは前層のノード数
n=100の場合は、上のグラフでは。Xavier→0.1、He→0.141程度なので、近いグラフをみると、良さそうなグラフになっています。
<MNIST学習でのReLUによる初期値の影響>
実際にMNISTのデータセットで学習をするときに初期値による変化をみてみます。以下がプログラムです。 ライブラリはこの圧縮ファイルをダウンロードし、解凍したディレクトリに下のプログラムを保存します。 またMNISTの展開済みの「mnist.pkl」も同じフォルダに保存します。
実行すると以下のグラフが作成されます。
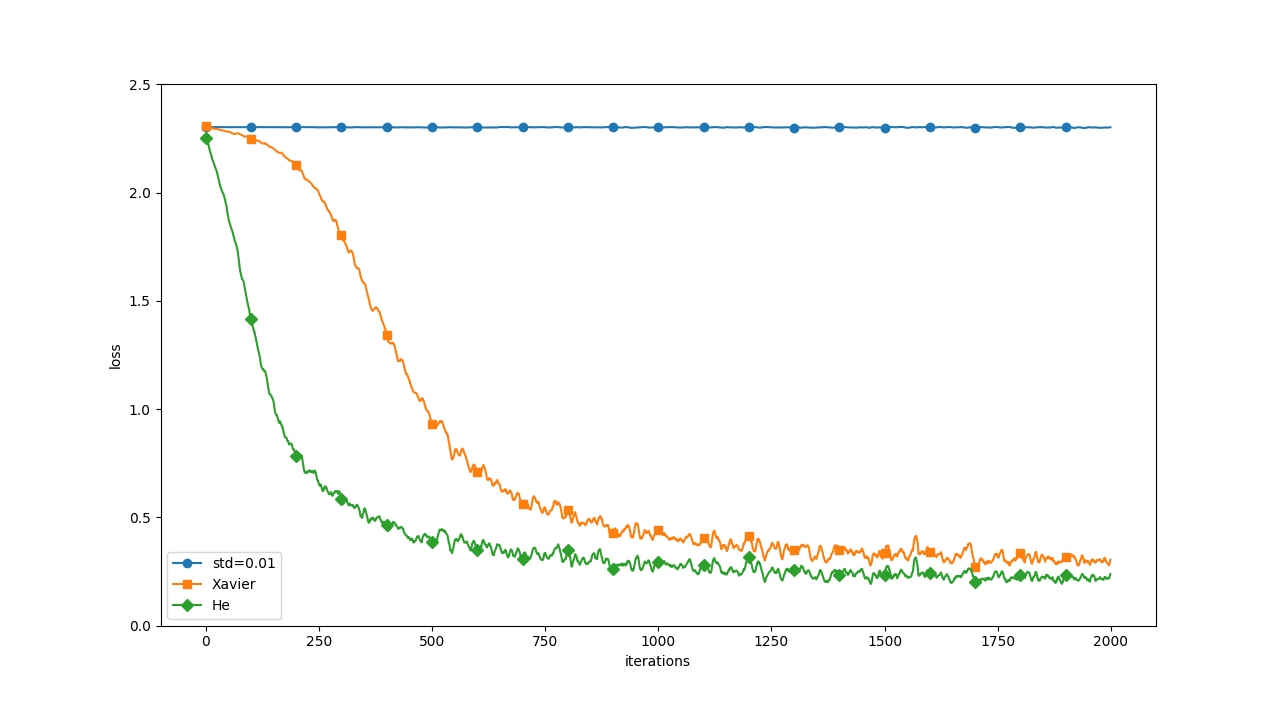
初期値が0.01の場合は、ほとんど学習が進んでいないため、誤差が減りません。Xavier、Heは進んでいきます。
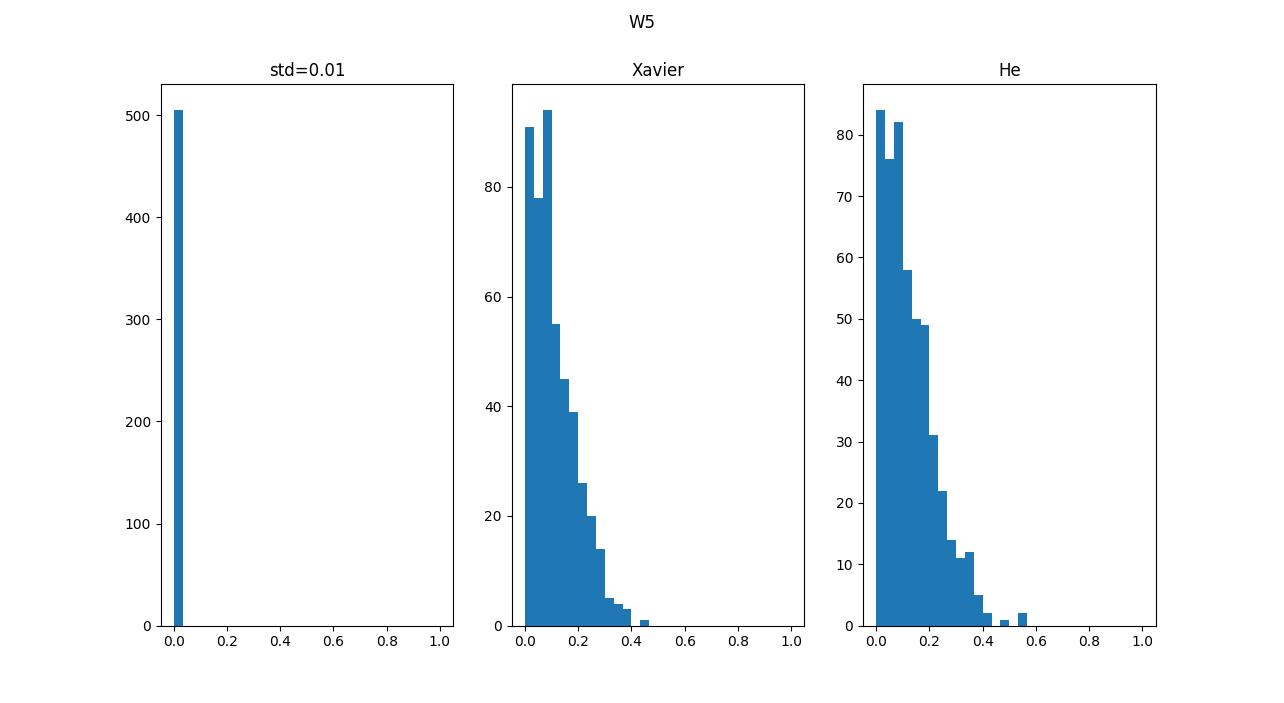
初期値が0.01での学習率が進まない理由は、W5の最後のアクティベーションの分布がほとんど0になっているためで、
他の2つと全然違うことがわかりました。
これは、仕事でも同じで、最初がダメだとうまくいきません。以前、財務状態が悪い会社へ設備投資をしたテーマでは、
あっという間に撤退に追い込まれました。機械学習で判断したら、きっと投資自体をやめるだろうなと思います。
機械学習を調べるとよく考えられているなぁと実感します。
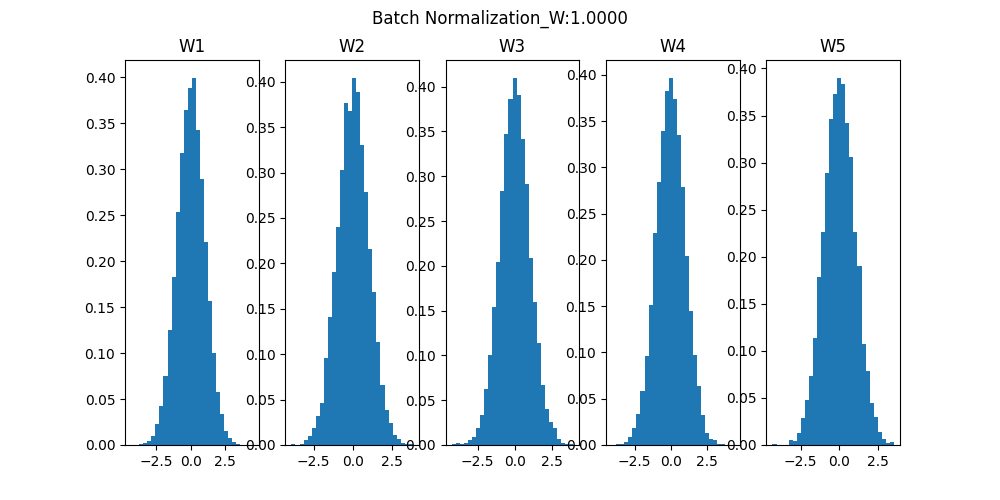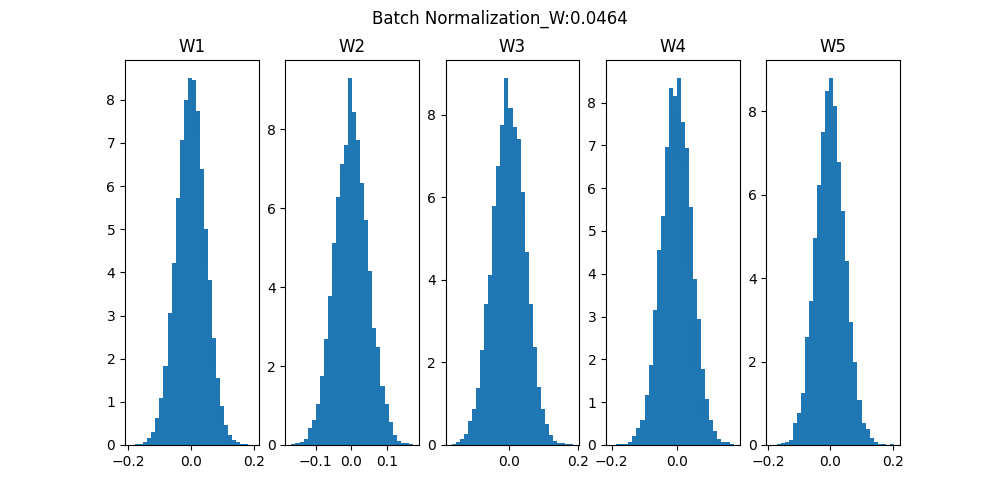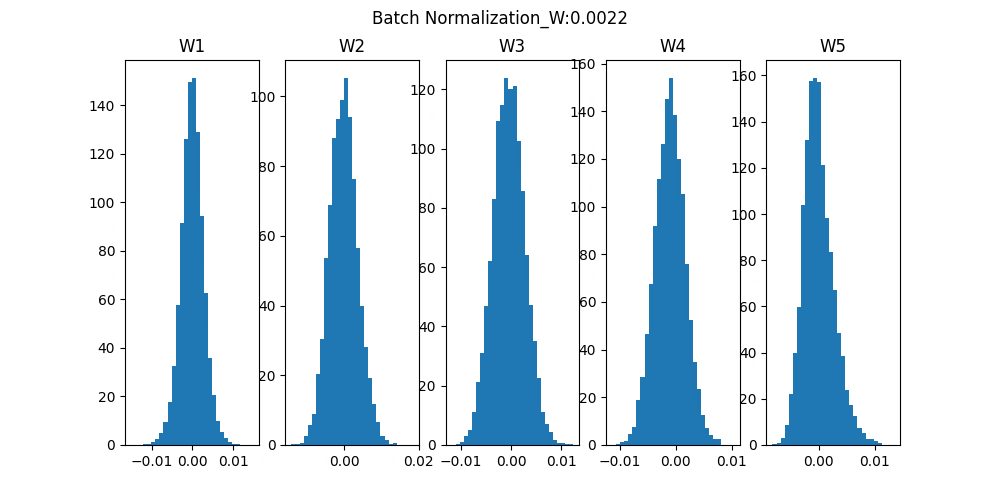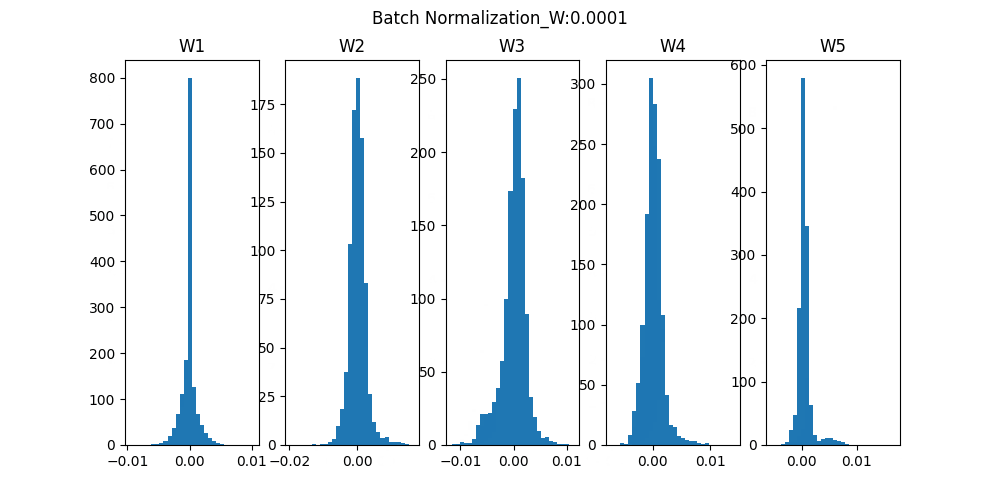
<Batch Normalization>
Batch Normalizationは重みの初期値にあまり影響しないように対応した学習方法です。ミニバッチ毎に平均0、分散1のデータ分布になるようにしています。
上と同じディレクトリに下のプログラムを保存します。
実行すると以下のグラフが作成されます。
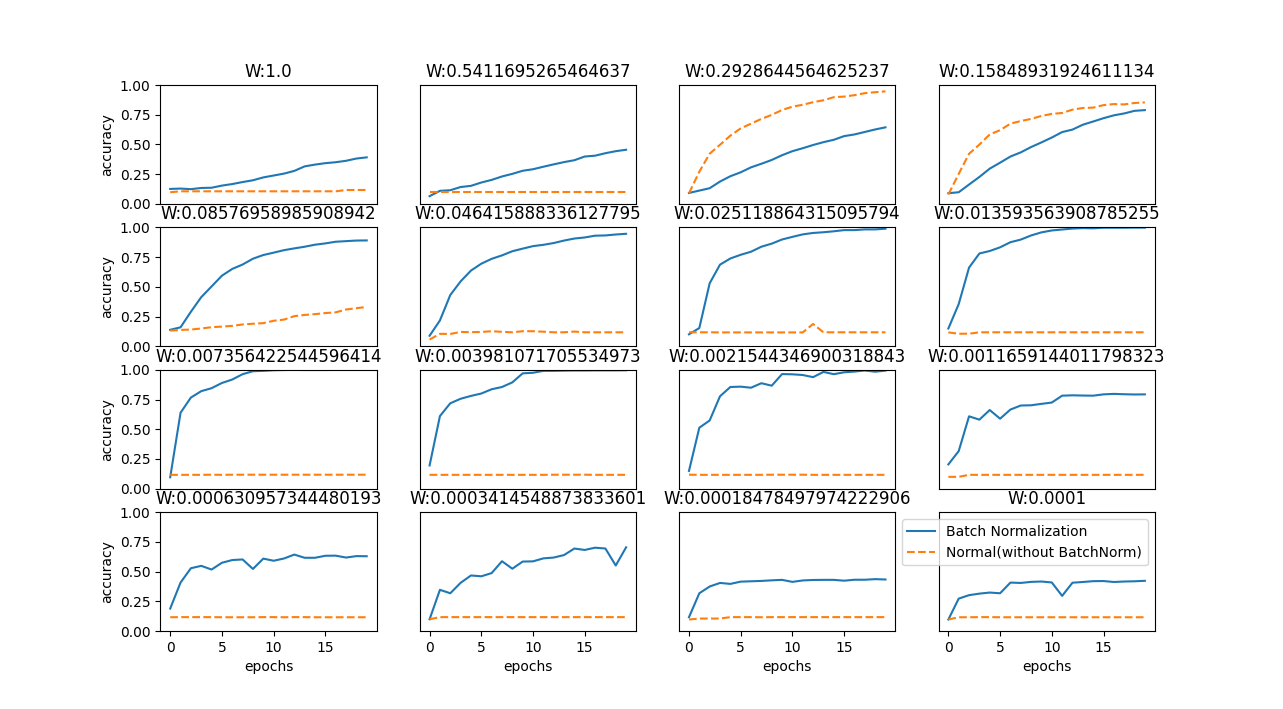
Batch Normalizationでは条件が悪い状態(重みの初期値が極端に大いor小さい)でも学習が進みますが、Normal ではほとんど進まない場合があります。
.gif)
それぞれの重み(W1~W5)のヒストグラムをみると、分布の幅が小さくても学習できているし、Normalよりも幅が狭くならないようになっています。
条件が悪くても頑張って結果をだせる優秀な「Batch Normalization」でした。
-------------