(第7回)誤差逆伝播法
前回のMNISTの学習で、せっかく作った順伝播法を使っていませんでした。実行してみるとわかりますが、 遅くて使えません。微分による勾配の計算をすると、すべてのパラメーターで同じような計算を繰り返して行うため、 非常に時間がかかります。第6回のプログラムの順伝播、誤差逆伝播法を入れ替えて実行すると良くわかります。
<簡単な逆伝播法>
まずは簡単な順伝播法と逆伝播法を確認します。順伝播はA~Dがきまれば、Zは容易に決まります。
逆伝播の場合は、連鎖律を考えると、∂z/∂zからAの方向へ戻る場合、約分され最終的には、∂z/∂aとなります。
∂zが1の場合(Zが1増える場合)、∂a=1/9となります。微分をしてみるとわかるのですが、逆伝播での乗算は、∂z/∂x=Yのように
X側にYが、加算は、∂x/∂a=1のように、何も変化しないという部分が特徴的です。
乗算は逆転して流れ、加算はそのまま流すという形です。
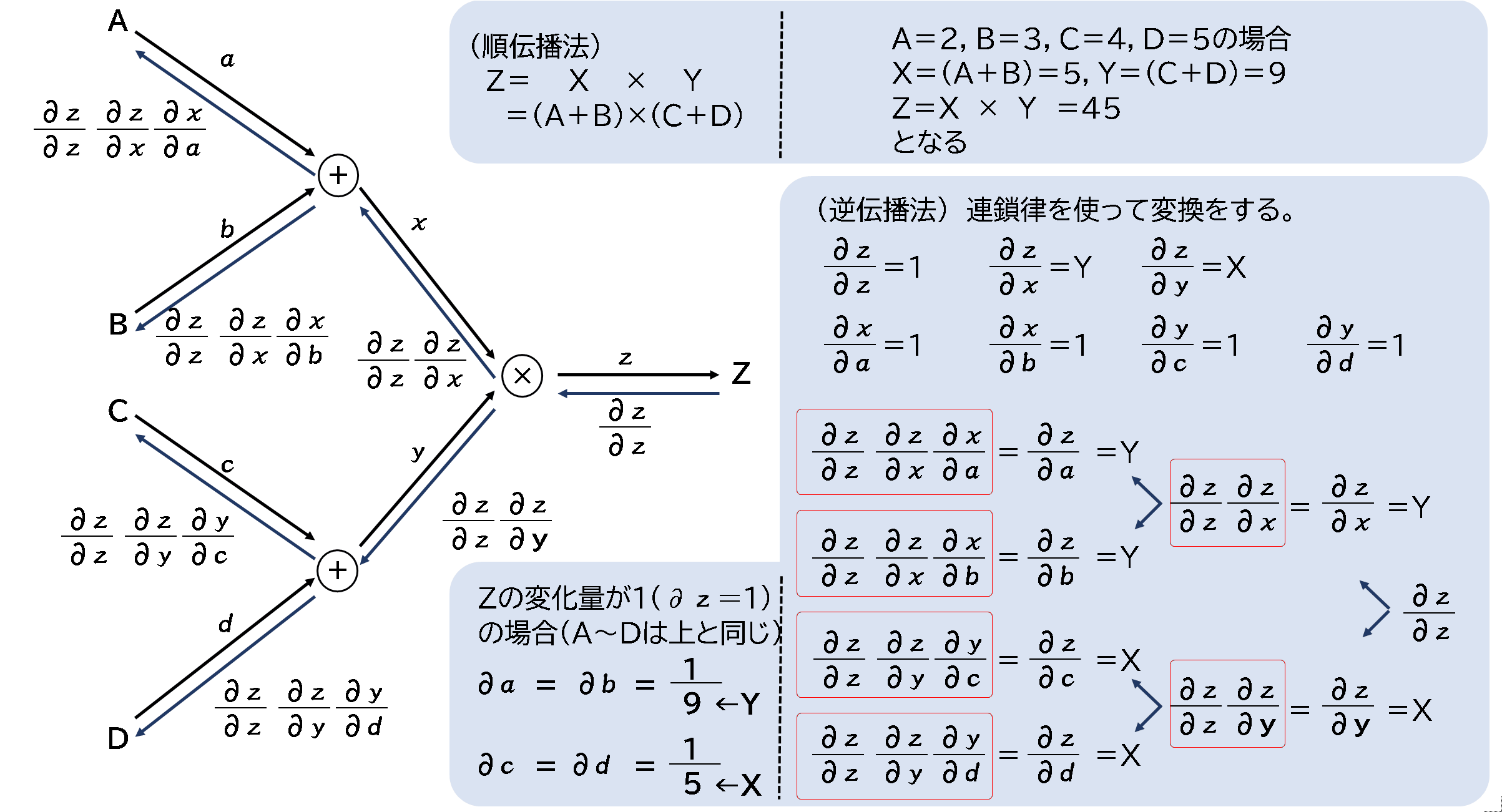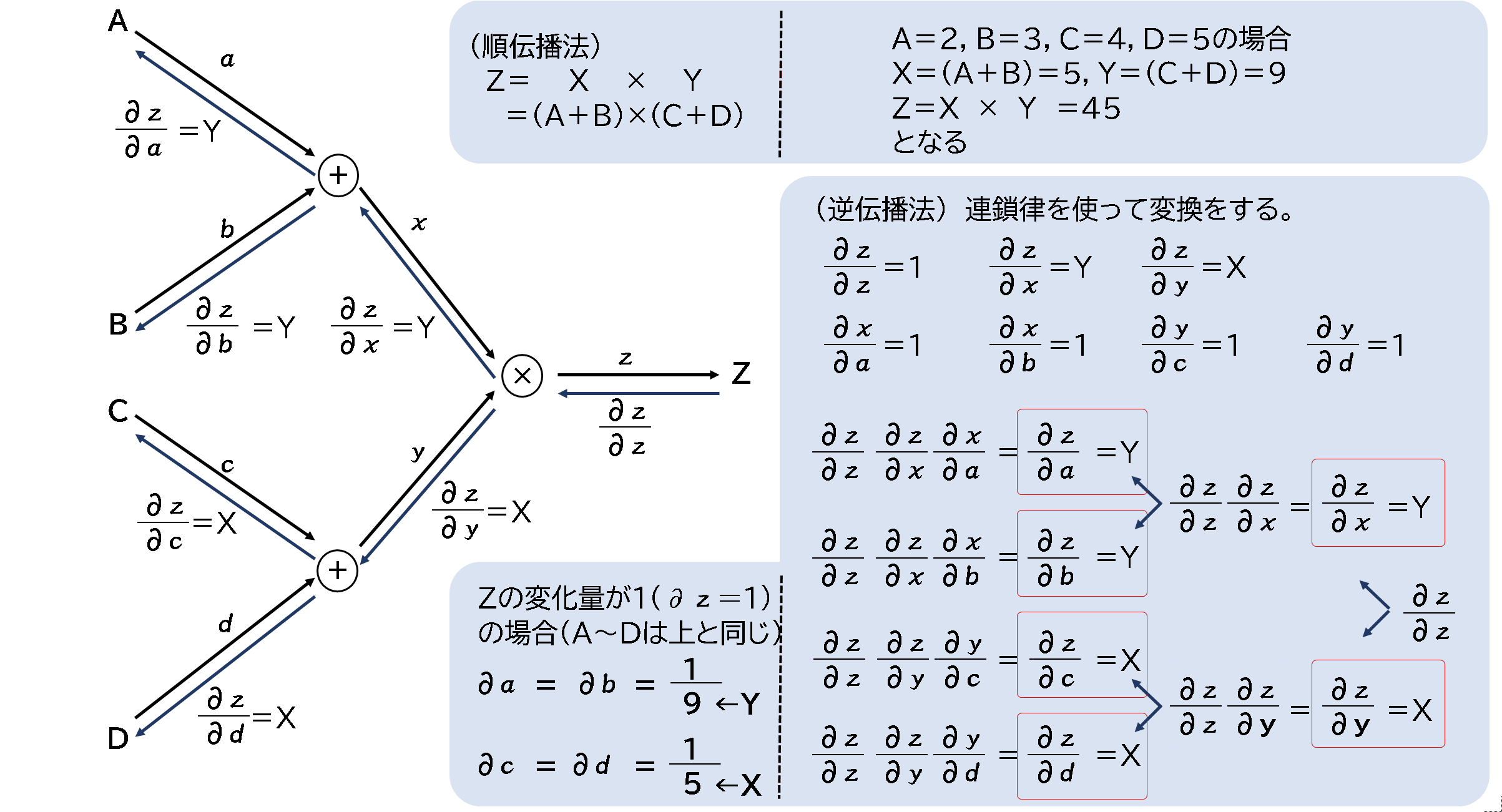
一見「逆伝播の方が複雑」と感じるかもしれません。しかし、順伝播はZを計算するためにA~Dをすべて計算する必要があります。 逆伝播はZから計算するため、A~Dを同時に算出できるため、計算回数が少なくすることが可能です。
Pythonで実行すると以下のようになります。
乗算レイヤの「MulLayer」と加算レイヤの「ADDLayer」クラスを作成し、それぞれに順伝播(forward)、逆伝播(backward)
関数を作成します。A~Dの数値を使って、順伝播を計算し、Zから逆方向にX,Yを計算、A~Dを計算することで、∂z=1(Zが1変化)
した時に、∂z/∂a=∂z/∂b=9、∂z/∂c=∂z/∂d=5となり、結果的には∂a=∂b=1/9、∂c=∂d=1/5となります。
これは、手で計算したときと同じ結果になっています。
今回の例は、4つの入力から2個の隠れ層を経由して、1個の出力でしたので、どっちから計算しても同じ計算量に感じるかもしれませんが、
実際の機械学習は多くの入力層(MNISTは784個)になりますので、はっきりとした差が感じられます。
<ReLU>
ReLU関数を誤差逆伝播法に対応できるようにします。加算、乗算については、上記で確認したとおり、逆伝播では加算はそのまま、
乗算は逆の出力になるという事が確認できました。ReLUは0以外は、そのまま流すということなので、逆伝播でも同じになります。
forward:[[2.,0.1],[2.,-0.2]]
backward:[[-2.,-0.1],[-2.,-0.2]]
逆伝播結果:[[-2. -0.1] [-2. 0. ]] ←順伝播で-0.2の部分だけが「0」となる。
順伝播で入力した時に「マイナス」がある場合は、逆伝播の時「0」になります。そのため、結果は、上記のように順伝播でマイナス以外が
算出されています。スイッチのような機能になっています。
<Sigmoid>
Sigmoid関数を誤差逆伝播法に対応できるようにします。第2回で調べた式は
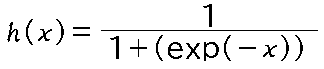
これを分解して微分していきます。
まずはシグモイド関数をrとtに置き換えます。
$\large{h(x)=\frac{1}{1+exp(-x)}}$
$\large{r=1+exp(-x)}$
$\large{t=\frac{1}{1+exp(-x)}=\frac{1}{r}=r^{-1}}$
次にそれぞれを微分します。
$\large{h(x)^{'}=\frac{∂t}{∂x}=\frac{∂t}{∂r}\cdot\frac{∂r}{∂x}}$
$\large{\frac{∂t}{∂r}=-r^{-2}}$
$\large{\frac{∂r}{∂x}=-exp(-x)}$
$h(x)^{'}$の式を展開して
$\large{h(x)^{'}=\frac{exp(-x)}{r^{2}}=\frac{exp(-x)}{(1+exp(-x))^{2}}=\frac{exp(-x)}{(1+exp(-x))^{2}}+\frac{1}{(1+exp(-x))^{2}}-\frac{1}{(1+exp(-x))^{2}}}$
$\large{=\frac{1}{(1+exp(-x))}\cdot(\frac{1+exp(-x)}{(1+exp(-x))}-\frac{1}{(1+exp(-x))})}$
$\large{=t\cdot(1-t)}$
となります。
Pythonでプログラムを作成すると以下のとおりになります。順伝播で求めたOUT(t)をそのまま使って、(1-t)・tで逆伝播が求められています。
グラフも出力すると、次のとおりになっています。
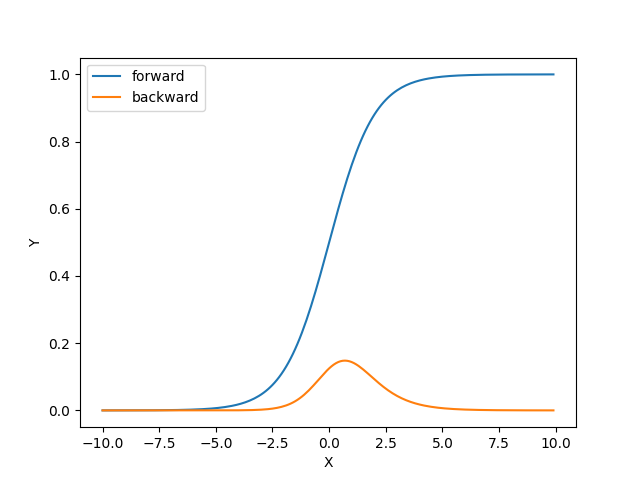
シグモイドの順伝播を微分したグラフになってます。
<Affine>
活性化関数では、1層の計算でしたが、実際は多層で処理をする必要があります。
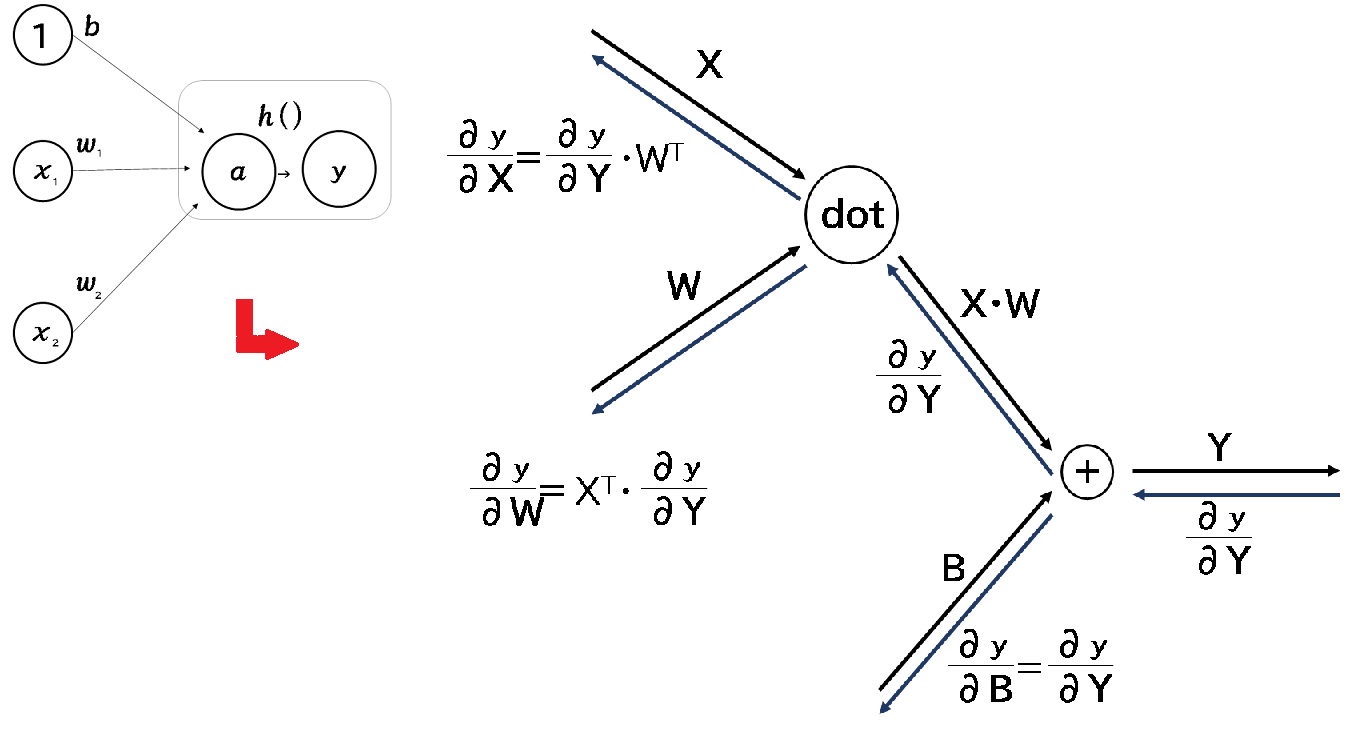
$\large{a=b+w_{1}x_{1}+w_{2}x_{2}}$ $\large{y=h(a)}$
↓
$\large{\frac{∂y}{∂X}=\frac{∂y}{∂Y}\cdot W^{T}}$ $\large{\frac{∂y}{∂W}=X^{T}\cdot \frac{∂y}{∂Y}}$ $\large{\frac{∂y}{∂B}=\frac{∂y}{∂Y}}$
上記のように、単層→多層で処理するために、Affine変換を行い、逆伝播法を計算します。逆伝播は微分で求めるのですが、 変換が大変なので、暗記することにします。
PythonでAffine変換を実行します。
まずは、第6回のメインプログラムを以下の物にします。ほとんど同じですが、最後に「import pickle」が追加されています。
これは、重みづけのデータをファイルに書き出すライブラリです。(便利)この重みづけのファイルを使えば、学習済みのモデルとして利用ができます。
この重みづけのW1,b1を利用するために学習をして、ファイルを書き出します。
「My_w1.pkl」「My_b1.pkl」の2個のファイルを使って、以下のプログラムを実行します。ペイントブラシで、56x56ピクセルの画像を作り、
同じフォルダに「test.png」と保存します。
実行すると自分の作成した画像が1度表示され、もう一度別の画像が表示されます。これは、「test.png」を順伝播して、出力されたデータを
逆伝播して、入力のデータを算出した結果です。
真っ黒の56X56を順伝播させたり、ランダムのダミーを学習したモデルで、順伝播→逆伝播したしてみると面白いかもしれません。100000回学習したモデル(w1,b1)とランダムのモデルでは、はっきりと違いが出ています。(以下)
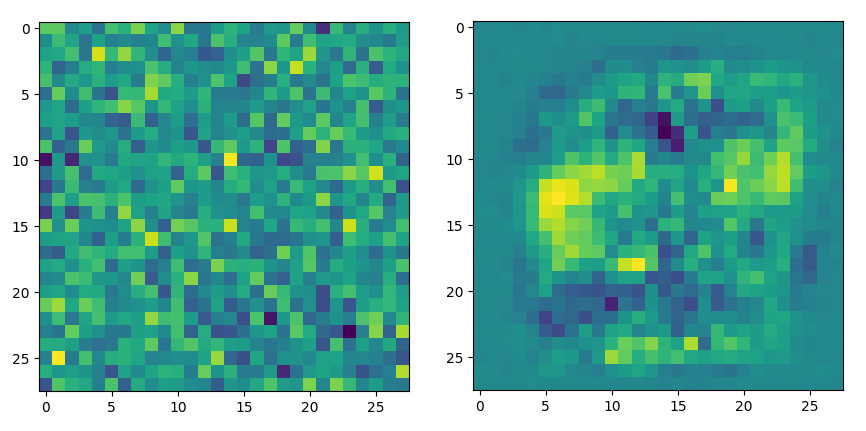
左がランダムのモデル。右が100000回学習したモデルで、97%程度の正解率です。学習したモデルは、文字を書く部分を重みづけしている ような画像になっています。ランダムデータのモデルは、ランダム感がでていて、おもしろいです。
<Softmax-with-Loss>
出力層のソフトマックスの逆伝播法についてです。
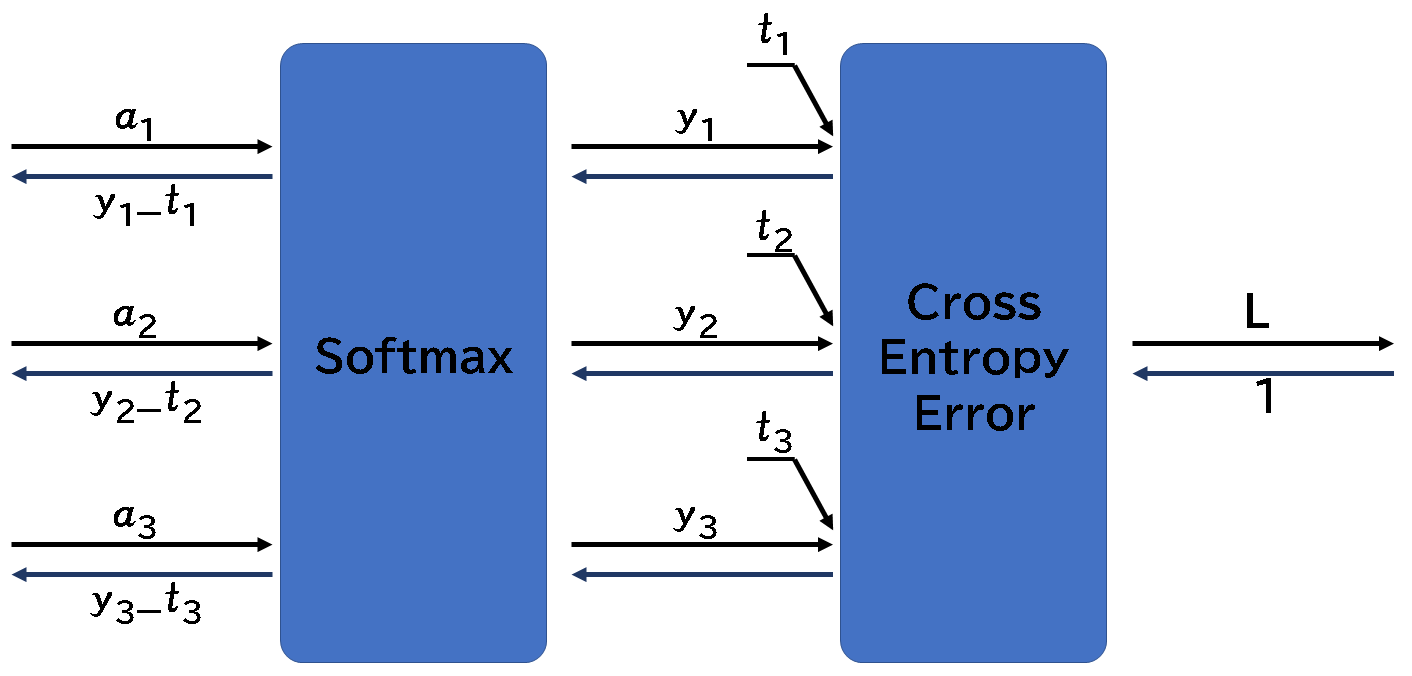
非常に単純なので驚きますが、$(y_{1}-t_{1},y_{2}-t_{2},y_{3}-t_{3})$になっています。
Pythonで実行してみるとわかりますが、逆伝播では、Softmaxの出力から、教師データを引き算した結果が得られます。
出力を比較すると
Softmax:[0.098,0.093,0.162,0.088,0.093,0.098,0.088,0.098,0.088,0.088]
逆伝播:[0.098,0.093,-0.837,0.088,0.093,0.098,0.088,0.098,0.088,0.088]
のように教師データが正解の部分がマイナスされていることがわかります。
-------------