(第11回)過学習
訓練データにばかり適用しすぎて、そのほかのデータにはうまく対応できない(=汎化性能が低い)学習を過学習と言います。
<ノルムについて>
過学習にならないように、重みの減衰をさせる(罰則を設ける)方法がありますが、ノルムについて理解しておく必要があります。
L1ノルムの正則化(Lasso回帰)、L2ノルムの正則化(Ridge回帰)などが機械学習を勉強するとよく出てくる言葉です。
〇L1ノルム
絶対値の和になります。
$||x_{1}||=|w_{1}|+|w_{2}|+|w_{3}|+・・・|w_{n}|$
〇L2ノルム
2乗の和になります。
$||x_{2}||=\sqrt{|w_{1}|^{2}+|w_{1}|^{2}+|w_{1}|^{2}+・・・|w_{n}|^{2}}$
下のプログラムを実行します。
まずは基準0,0→4,3の矢印が表示されます。(4,3)の場合L0ノルムは0以外の数値が2個あるので、「2」となり、L1は「7」、L2は「5」です。 ノルムの数が大きくなると徐々に四角形になります。
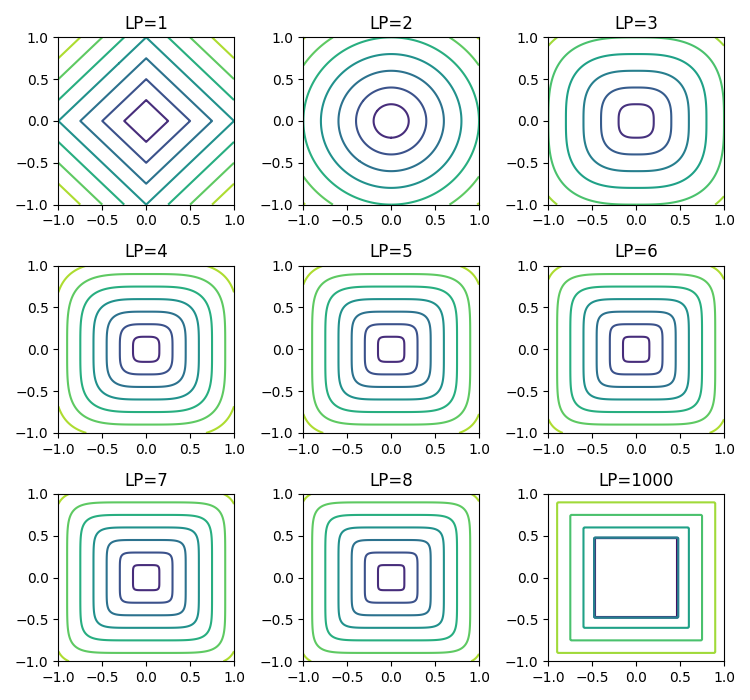
XとYがノルムの数値によって、計算された高さを等高線で表示しています。
$\large{||Z_{p}||=\sqrt[p]{(|x|^{p}+|y|^{p}}}$
p=1(L1)、p=2(L2)で、p=∞(L∞)も利用される事があるようです。
通常はL2ノルムが良く利用されるので、この形で正則化を行い重みを減衰させることで、過学習を発生させないようにしています。
<Weight Decay>
損失関数に罰則を加える手法です。L2ノルムをペナルティとして利用します。
$\LARGE{\frac{1}{2}λW^{2}}$
λは正則化の強さをコントロールするハイパーパラメータ
1/2はW^2を微分した結果をλWにするための調整用の定数
この項を損失関数に加えて重みが大きく変更されないようにしています。
下のプログラムを実行します。(第10回と同じディレクトリに保存して実行します)
multi_layer_net.pyの
「weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2)」
が損失関数に加算している部分になります。
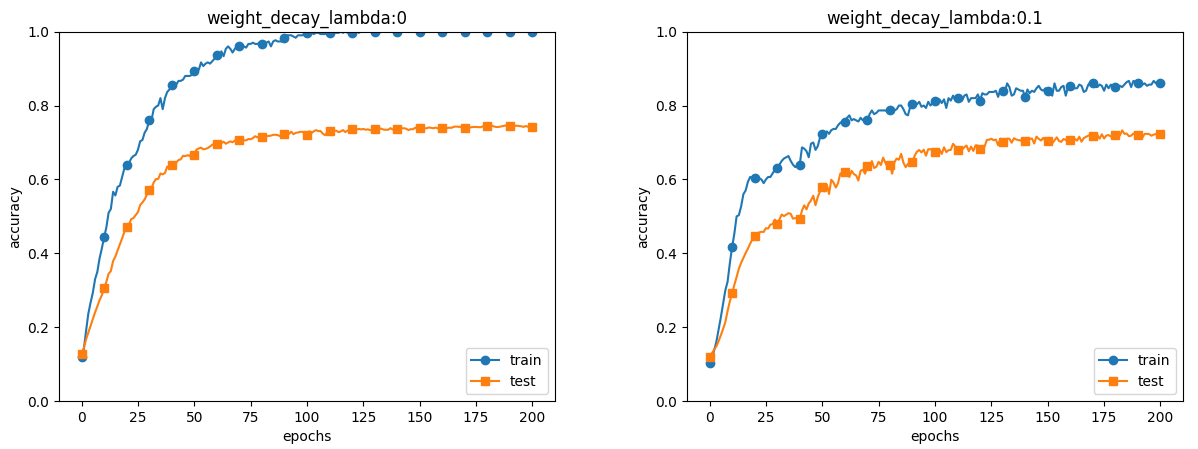
訓練データとテストデータの精度をweight_decay_lambdaの数値が0(なし)と0.1で比較すると、訓練データが100%に 到達しなくなっています。テストデータの正解率はどちらも変わりません。訓練データとテストデータの正解率の差が小さくなっており、 過学習が抑制できていることがわかります。
<Dropout>
ニューラルネットワークのニューロンをランダムで選択して、その経路を遮断してしまう方法です。
入力と同じ形状の配列をランダムで形成し、その数値が、doropout_ratioより大きいもニューロンのみを使用します。(ratio以下の物は遮断)
下のプログラムを実行します。(第10回と同じディレクトリに保存して実行します)
訓練データとテストデータの精度をDoropoutの有無で比較すると、訓練データが100%に 到達しなくなっています。dropout_ratio=0.2で行っていますが、訓練データとテストデータの正解率の差が小さくなっており、 過学習が抑制できていることがわかります。

-------------