(第4回)損失関数
ニューラルネットワークで入力から出力を得ることができるようになりましたが、ほしい出力が得られる、重み(w)、バイアス(b)を決める必要があります。
しかし、考え無しに計算をしても、良い結果は得られません。その目標にする数値が損失関数となります。損失関数を小さくすることこそが、目標になります。
損失関数の「2乗和誤差」「交差エントロピー誤差」について調べます。
<2乗和誤差>
ニューラルネットワークで出力(ソフトマックス)された数値と正解の数値の差異を誤差として算出します。ここで正解の数値という物が「教師データ」となります。
具体的には、
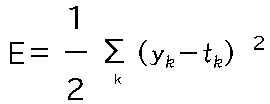
のように、(ニューラルネットワークの出力と正解の差の2乗の総和)/2となります。
またPythonで計算すると以下のようになります。正解が2の場合で、出力も2の場合は、0.1程度の誤差ですが、
出力が7になると0.6程度の誤差になります。
<交差エントロピー誤差>
2乗和誤差は、正解ラベル以外の出力(ソフトマックス)も影響を受けますが、交差エントロピー誤差は、正解ラベルの誤差のみを得る関数になります。
具体的には、
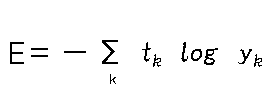
のように、正解のtがlogの前にあるため、正解のラベル以外は0になります。(tkはone-hot表現)logは底がeの自然対数(計算機だとln(yk))のため、
正解の1に近づくほど0になります。
またPythonで計算すると以下のようになります。正解が2の場合で、出力も2の場合は、0.5程度の誤差ですが、
出力が7になると2.3程度の誤差になります。
次は交差エントロピー誤差+ミニバッチ学習を行います。複数個の損失関数を計算できるようになります。
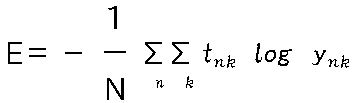
のように、n個の交差エントロピー誤差の合計を計算します。
Pythonで計算すると以下のようになります。正解ラベル①は、10個の出力があったら、[0,0,1,0,0,0,0,0,0,0,]で、
正解ラベル②は[2]のようにラベルで表現した場合になります。
出力は以下のようになります。
3個の誤差を計算した結果になります。正解ラベル①と②で、1個毎の出力は、それぞれ異なっておりますが、最終的な出力は、1.94と同じ結果が出力されています。
np.random.choice(1000,10)のように1000個のデータから10個を抽出して、計算することができるようになります。
機械学習では、正解率を使って学習されているように感じますが、この誤差を小さくすることが機械学習の本質です。会社の業績を上げるために「良かった点」に着目
して計画を立てがちですが、「悪かった点」に着目してその改善の計画をすすめる方が良い会社をつくる近道なのかもしれません。(機械学習で会社を運営したらきっとそうするハズです。)
-------------