(第9回)パラメータの更新(最適化)
損失関数の値を小さくするために学習を行うのですが、効率よくパラメータを見つける必要があります。これを最適化と言い、学習率や いままで調べた確率的勾配降下法(SGD)以外にも色々な方法があります。
<関数>
これから進める方法は、以下の関数の最小値を求めることを目標としてすすめます。
$\Large{f(x,y)=\frac{1}{20}x^{2}+y^{2}}$
この関数をグラフにする場合は、このプログラムのとおりになります。
<SGD>
SGDは確率的勾配降下法という手法になります。これまではこの方法を使っていましたが、簡単であるため欠点があります。
$\Large{W←W-η\frac{∂L}{∂W}}$
「←」は値を更新するという意味で、重みのパラメーターを「学習率(η)×勾配(∂L/∂W)」を引き算しながら
パラメーターを更新して行きます。
プログラムは以下のとおり
実行すると以下のグラフが作成されます。
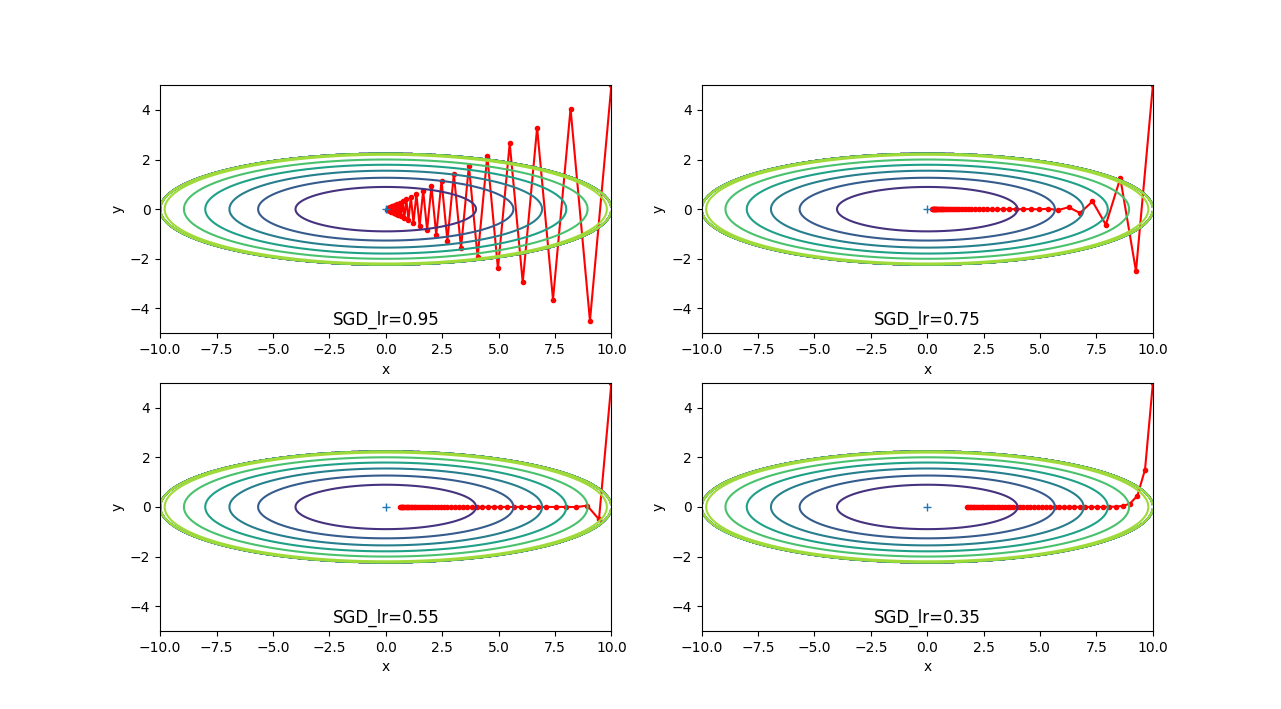
50回パラメータを更新して最小値を目標にすすみますが、学習率が低くなると、 中央に到達していないことがわかります。学習率が大きいと中央に到達できますが、ギザギザが大きくなり効率が悪い事が 分かります。yとxの傾きの大きさが20倍違うため、ギザギザになってしまいます。
<Momentum>
Momentumはすり鉢にいれたボールが中央に転がるような動きをする方法です
$\Large{v←αv-η\frac{∂L}{∂W}}$
$\Large{W←W+v}$
vという変数が追加され、αvによって、変化量が小さいx方向もしっかりパラメータが更新されるようになります。
プログラムは以下のとおり
実行すると以下のグラフが作成されます。
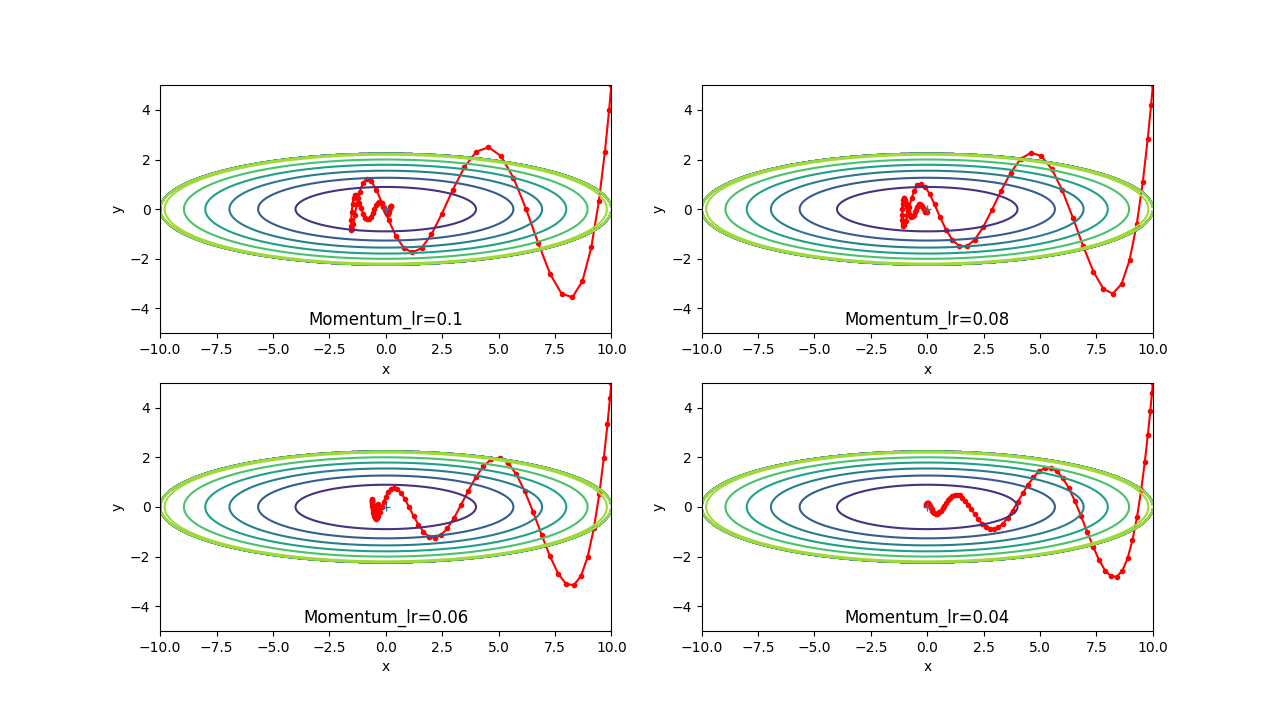
70回パラメータを更新しています。学習率が0.1では、通り過ぎて戻り、0.04では直接中央に到達しています。 ボールが中央ような動きになっています。αは0.9に設定していますが数値を変更すると到達しなくなったりします。
<AdaGrard>
AdaGrardは学習率ηを固定ではなく、変化させる方法です。学習率を減衰させることで、最初は大きく、 徐々に小さくすることで、効率よくパラメータの更新を行います。
$\Large{h←h+\frac{∂L}{∂W}⦿\frac{∂L}{∂W}}$
$\Large{W←W-η\frac{1}{\sqrt{h}}\frac{∂L}{∂W}}$
⦿は行列の要素ごとの掛け算を意味しており、勾配の2乗和として、hという変数にします。
$\frac{1}{\sqrt{h}}$を掛け算することで、大きく変化した要素の学習率が小さくなるようになります。
プログラムは以下のとおり
実行すると以下のグラフが作成されます。
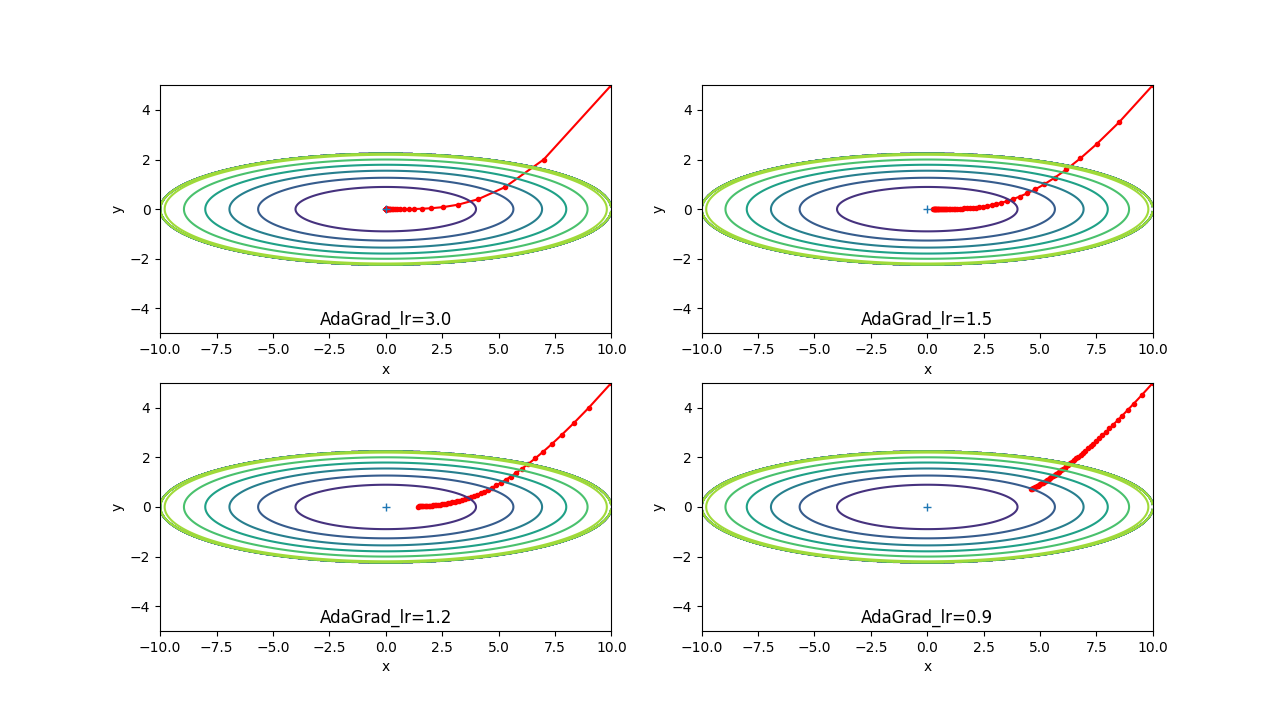
50回パラメータを更新しています。学習率が3.0で直接中央に到達していますが、学習率の初期が低いと 中央に到達していません。しかし、どの学習率でも同じような形になるので、回数を多くすれば、結果的に同じ用な モデルが作成されると予想できます。
<RMSprop>
RMSpropはAdaGrardの学習率を0にならないようにする方法です。AdaGrardは学習が進むと、学習率ηが減衰し続けて、 最終的には0に近くなり、学習が進まなくなってしまいます。最新の勾配の情報が大きく反映され、過去の勾配情報の影響を小さくします。
$\Large{h←hβ+(1-β)\frac{∂L}{∂W}⦿\frac{∂L}{∂W}}$
$\Large{W←W-η\frac{1}{\sqrt{h}}\frac{∂L}{∂W}}$
AdaGrardにβという変数が加わり、hβ、(1-β)によって、hが直近と過去の勾配の影響の度合いを調整しています。
プログラムは以下のとおり
実行すると以下のグラフが作成されます。
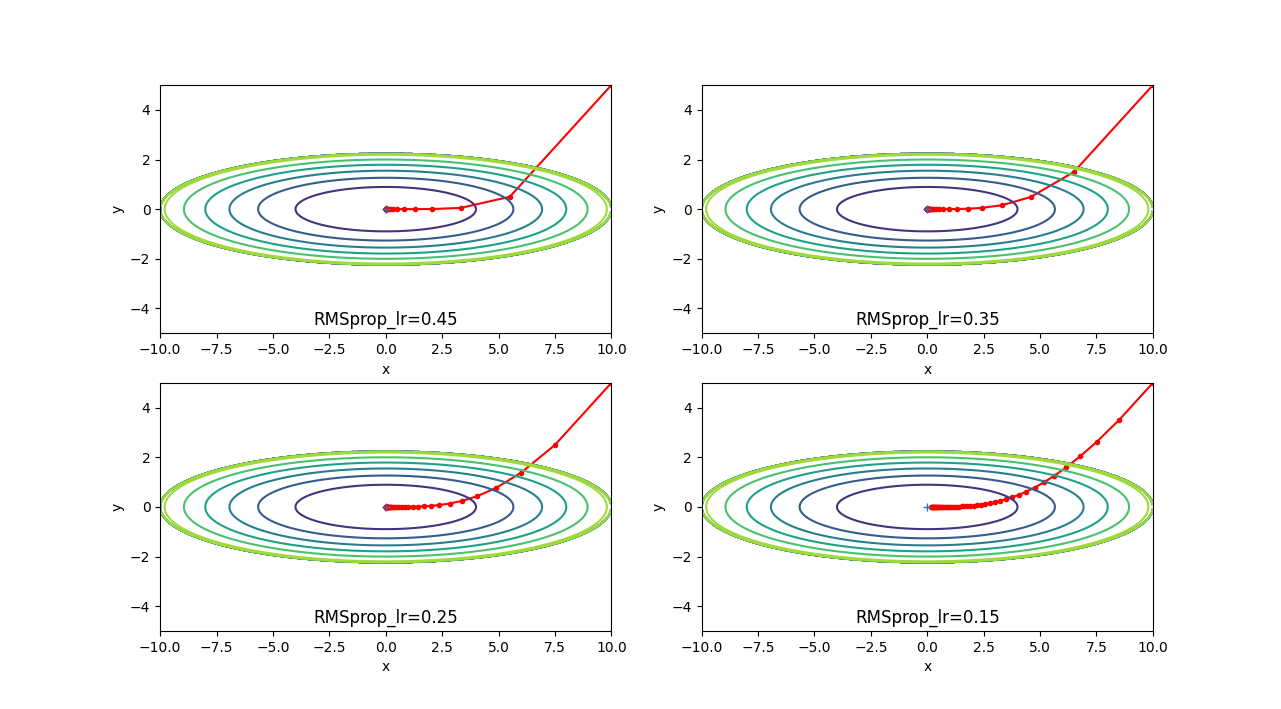
50回パラメータを更新しています。学習率が0.5を超えるとあまりよくなさそうな更新の挙動ですが、 基本的には、AdaGrardと同じような更新の挙動になっています。
<Adam>
AdamはAdaGrard+Momentumの手法です。
$\Large{m←(1-β_{1})(\frac{∂L}{∂W}-m)}$
$\Large{v←(1-β_{2})(\frac{∂L}{∂W}⦿\frac{∂L}{∂W}-v)}$
$\Large{W←W-η\frac{m}{\sqrt{v}+10^{-7}}}$
学習率η、$β_{1}$、$β_{2}$の3つのハイパーパラメータを設定としています。標準的には
$β_{1}$=0.9、$β_{2}$=0.999のようです。
プログラムは以下のとおり
実行すると以下のグラフが作成されます。
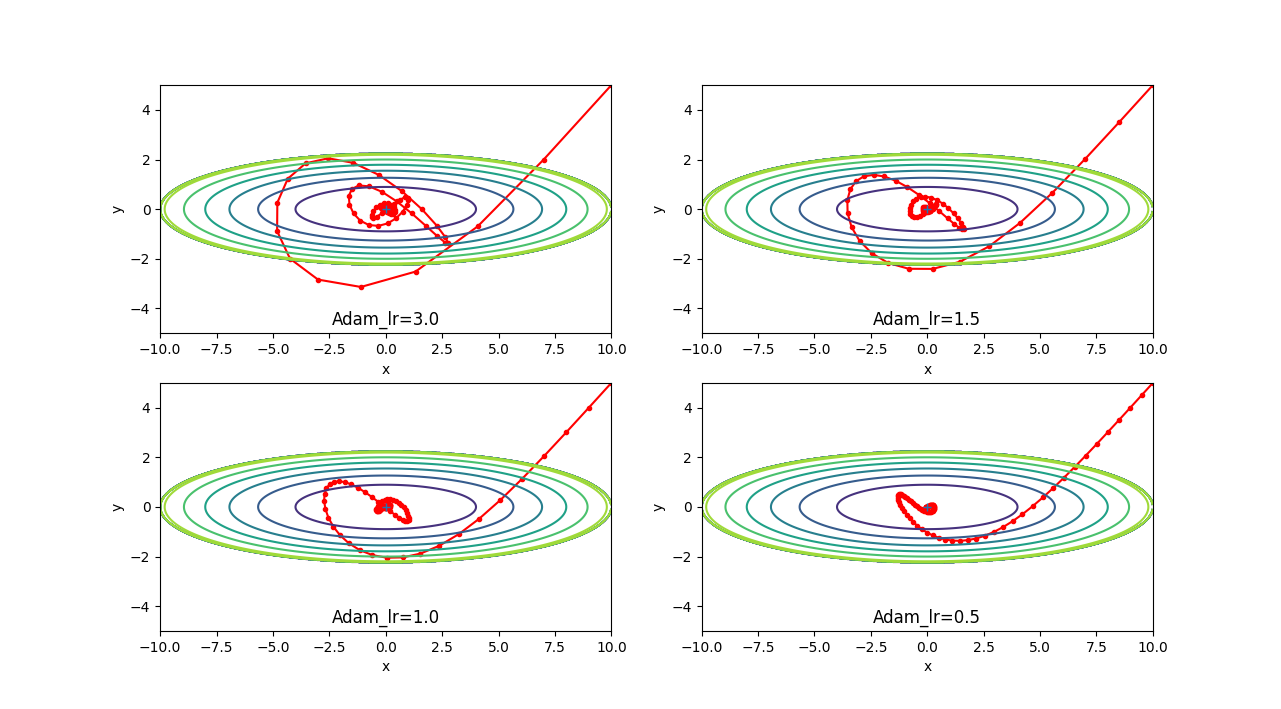
100回パラメータを更新しています。どの学習率でも中央に向かおうという意思のようなものがあり、これが良さそうと感じますが、 実際はこれが優秀という事はなく、どんなデータか?どの手法を使うか?によって、変わるようです。
<比較>
いままでの手法を2000回学習したときの誤差を比較します。Nesterovの加速法も加えて、比較します。
以下のプログラムをダウンロードして保存します。MNISTのデータセットも必要なので、展開済みの「mnist.pkl」も同じフォルダに
保存しておきます。
mnist.py
multi_layer_net.py
optimizer.py
util.py
プログラムは以下のとおり
実行すると以下のグラフが作成されます。
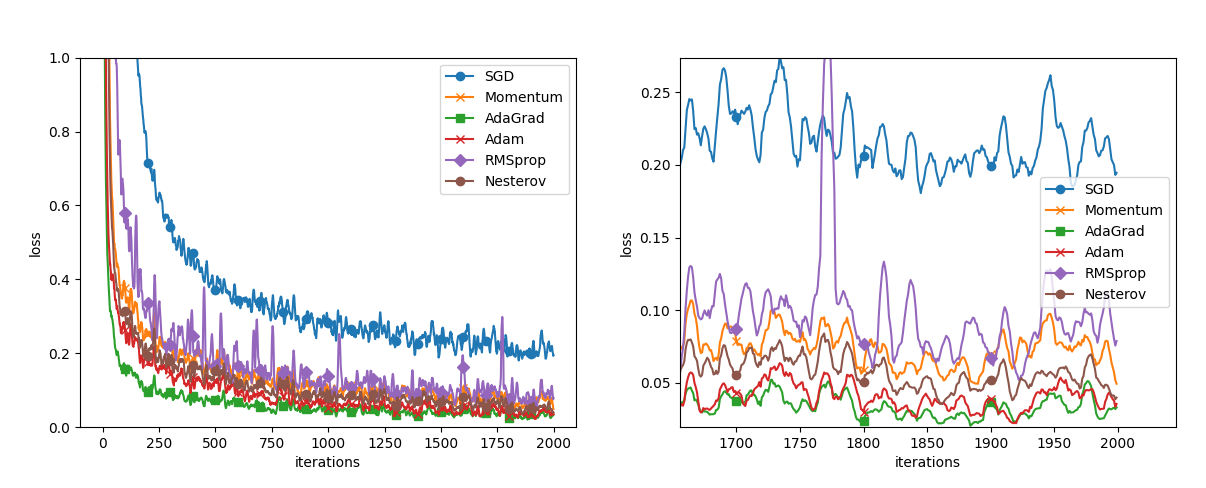
MNISTのモデルの学習を2000回計算したときの誤差のグラフです。最後の方を拡大すると、AdaGardが良さそうに
見えますが、学習率などでも異なるので、一概には言えません。しかし手法によって差異が生まれるという事を考えて
学習をさせる必要があるという事なんだろうと思います。
また、出力された後に、各手法のファイルが生成されます。これはモデルファイルとなっており、読みだせば、手書きの文字を
認識させることも可能です。同じフォルダに手書きをした「test.png」のファイルを準備して実行すると判別できます。
-------------